You have a frequently asked questions (FAQ) PDF file.
You need to create a conversational support system based on the FAQ.
Which service should you use?
You need to predict the sea level in meters for the next 10 years.
Which type of machine learning should you use?
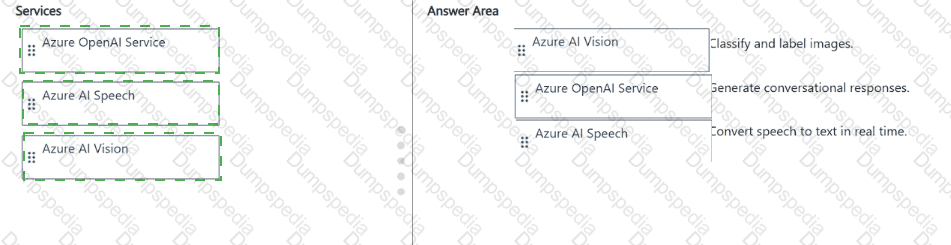
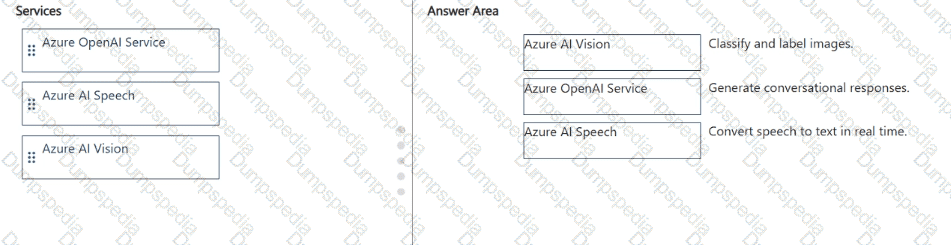
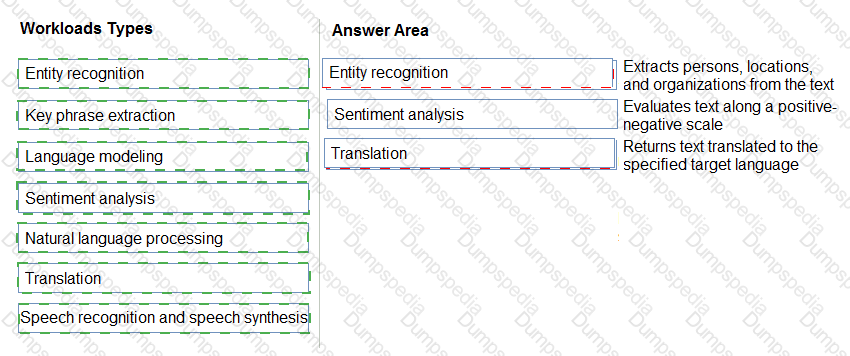
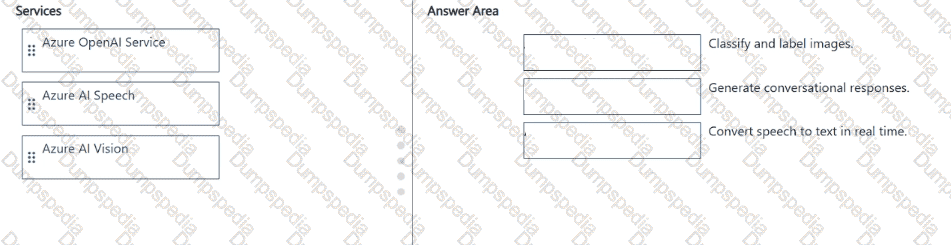
Match the Azure Al service to the appropriate generative Al capability.
To answer, drag the appropriate service from the column on the left to its capability on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
You need to create a customer support solution to help customers access information. The solution must support email, phone, and live chat channels. Which type of Al solution should you use?
You have a dataset that contains experimental data for fuel samples.
You need to predict the amount of energy that can be obtained from a sample based on its density.
Which type of Al workload should you use?
You plan to create an Al application by using Azure Al Foundry. The solution will be deployed to dedicated virtual machines. Which deployment option should you use?
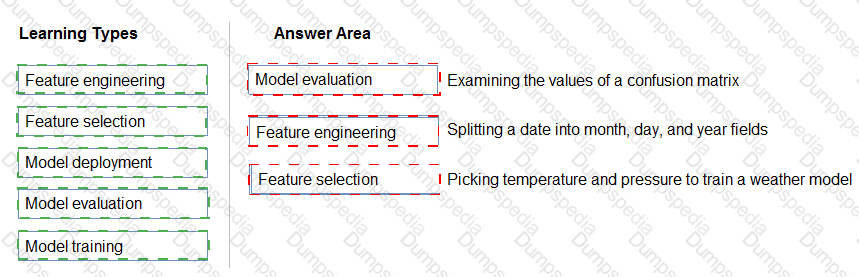
Which two components can you drag onto a canvas in Azure Machine Learning designer? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
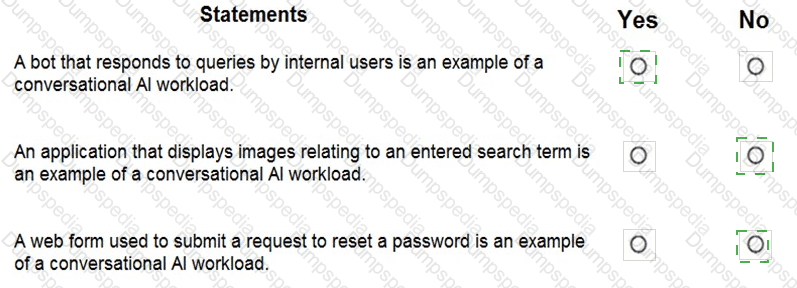
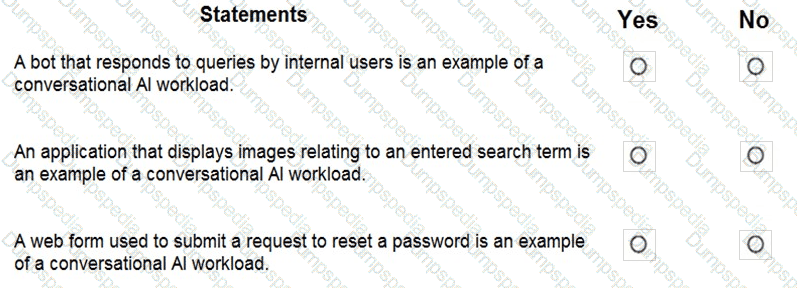
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
You use Azure Machine Learning designer to publish an inference pipeline.
Which two parameters should you use to consume the pipeline? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You need to develop a mobile app for employees to scan and store their expenses while travelling.
Which type of computer vision should you use?
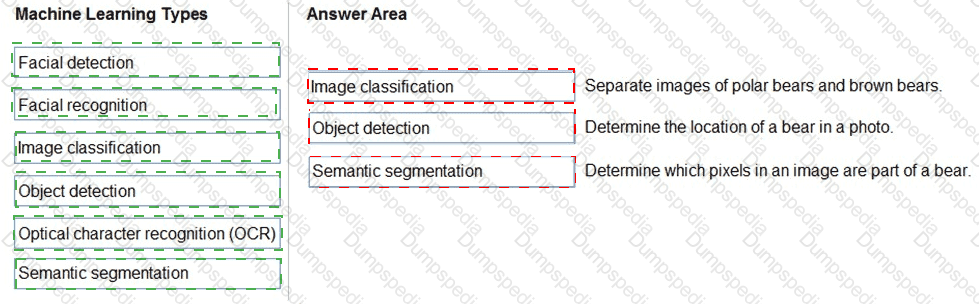
You are building a tool that will process images from retail stores and identity the products of competitors.
The solution must be trained on images provided by your company.
Which Azure Al service should you use?
You need to create a clustering model and evaluate the model by using Azure Machine Learning designer. What should you do?
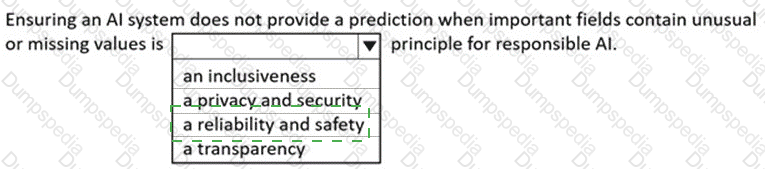
You are building an AI-based app.
You need to ensure that the app uses the principles for responsible AI.
Which two principles should you follow? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You are building a tool that will process images from retail stores and identify the products of competitors.
The solution will use a custom model.
Which Azure Cognitive Services service should you use?
You have the process shown in the following exhibit.
Which type AI solution is shown in the diagram?
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

What should you use to explore pretrained generative Al models available from Microsoft and third-party providers?
You have a database that contains a list of employees and their photos.
You are tagging new photos of the employees.
For each of the following statements select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

You are evaluating whether to use a basic workspace or an enterprise workspace in Azure Machine Learning.
What are two tasks that require an enterprise workspace? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Match the machine learning tasks to the appropriate scenarios.
To answer, drag the appropriate task from the column on the left to its scenario on the right. Each task may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.

Match the types of computer vision to the appropriate scenarios.
To answer, drag the appropriate workload type from the column on the left to its scenario on the right. Each workload type may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
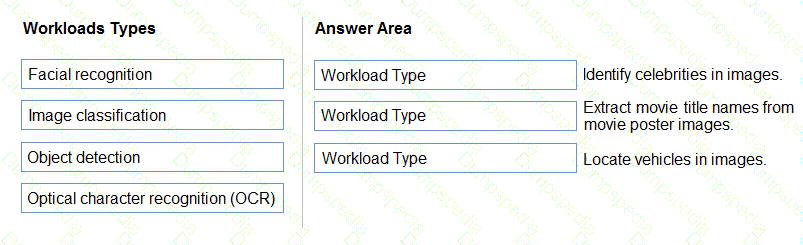
You need to implement a pre-built solution that will identify well-known brands in digital photographs. Which Azure Al sen/tee should you use?
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

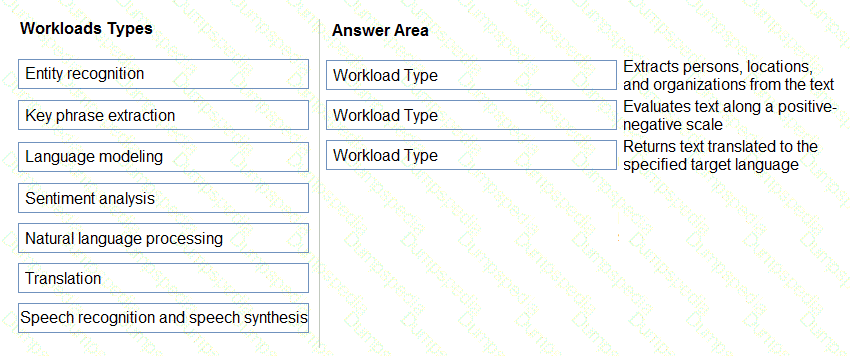
Match the types of AI workloads to the appropriate scenarios.
To answer, drag the appropriate workload type from the column on the left to its scenario on the right. Each workload type may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
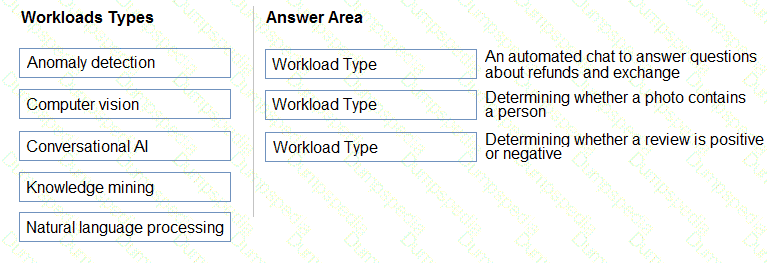
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.

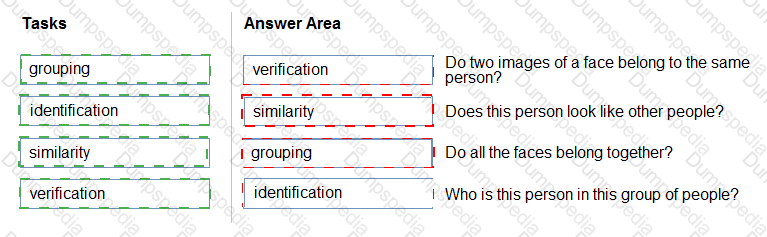
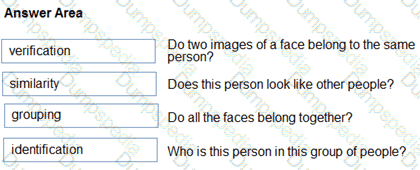
Match the facial recognition tasks to the appropriate questions.
To answer, drag the appropriate task from the column on the left to its question on the right. Each task may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE; Each correct selection is worth one point.

You are building a knowledge base by using QnA Maker. Which file format can you use to populate the knowledge base?
You have a dataset that contains the columns shown in the following table.
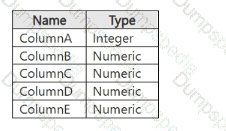
You have a machine learning model that predicts the value of ColumnE based on the other numeric columns.
Which type of model is this?
You need to develop a chatbot for a website. The chatbot must answer users questions based on the information m the following documents
• A product troubleshooting guide m a Microsoft Word document
• A frequently asked questions (FAQ) list on a webpage
Which service should you use to process the documents?
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.

Match the types of machine learning to the appropriate scenarios.
To answer, drag the appropriate machine learning type from the column on the left to its scenario on the right. Each machine learning type may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
Which OpenAI model does GitHub Copilot use to make suggestions for client-side JavaScript?
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Match the tool to the Azure Machine Learning task.
To answer, drag the appropriate tool from the column on the left to its tasks on the right. Each tool may be used once, more than once, or not at all
NOTE: Each correct match is worth one point.

You need to provide customers with the ability to query the status of orders by using phones, social media, or digital assistants.
What should you use?
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

You need to predict the population size of a specific species of animal in an area.
Which Azure Machine Learning type should you use?
Match the types of natural languages processing workloads to the appropriate scenarios.
To answer, drag the appropriate workload type from the column on the left to its scenario on the right. Each workload type may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
Your company wants to build a recycling machine for bottles. The recycling machine must automatically identify bottles of the correct shape and reject all other items.
Which type of AI workload should the company use?
What can be used to analyze scanned invoices and extract data, such as billing addresses and the total amount due?
You have an Internet of Things (loT) device that monitors engine temperature.
The device generates an alert if the engine temperature deviates from expected norms.
Which type of Al workload does the device represent?
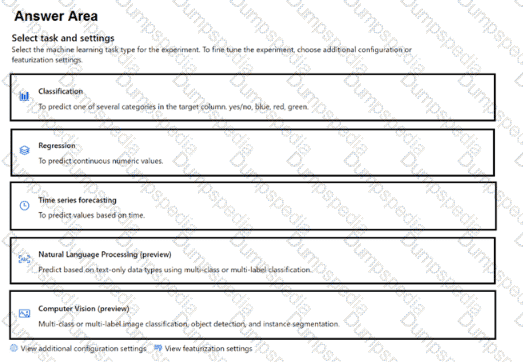
You have a large dataset that contains motor vehicle sales data.
You need to train an automated machine learning (automated ML) model to predict vehicle sale values based on the type of vehicle.
Which task should you select? To answer, select the appropriate task in the answer area.
NOTE: Each correct selection is worth one point.
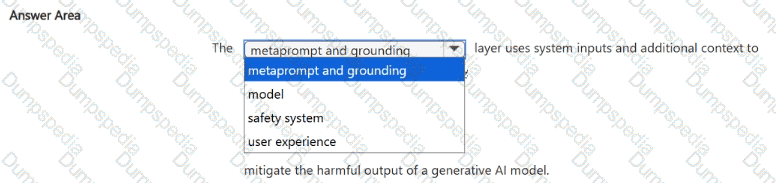
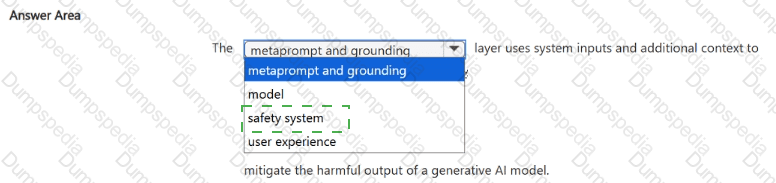
You are building an AI system.
Which task should you include to ensure that the service meets the Microsoft transparency principle for responsible AI?
A smart device that responds to the question. " What is the stock price of Contoso, Ltd.? " is an example of which Al workload?
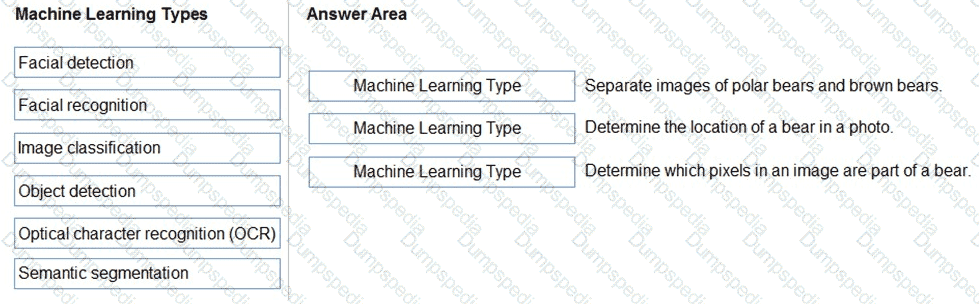
Match the types of computer vision workloads to the appropriate scenarios.
To answer, drag the appropriate workload type from the column on the left to its scenario on the right. Each workload type may be used once more than once, or not at all.
NOTE: Each correct match is worth one point.

What is the maximum image size that can be processed by using the prebuilt receipt model in Azure Al Document Intelligence?
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Extracting relationships between data from large volumes of unstructured data is an example of which type of Al workload?
You use natural language processing to process text from a Microsoft news story.
You receive the output shown in the following exhibit.

Which type of natural languages processing was performed?
You are processing photos of runners in a race.
You need to read the numbers on the runners’ shirts to identity the runners in the photos.
Which type of computer vision should you use?
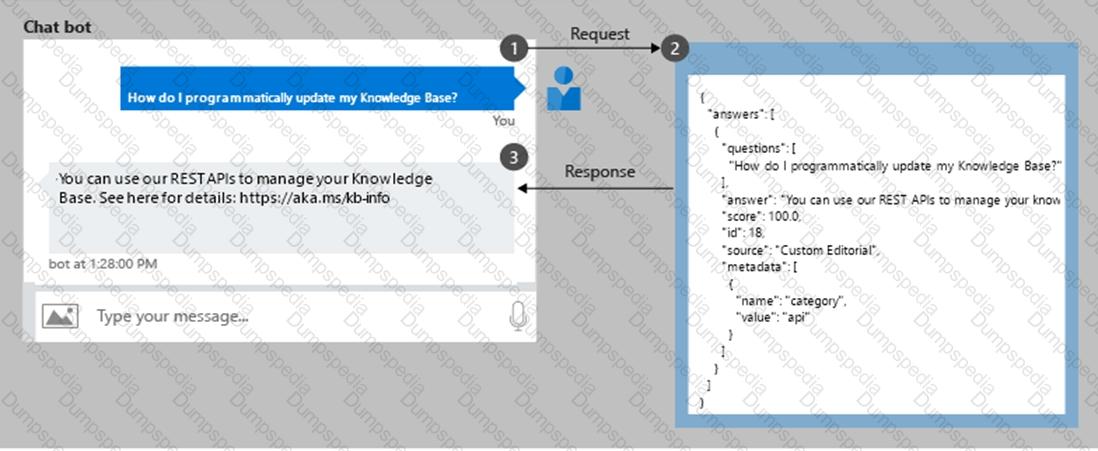
You have a custom question answering solution.
You create a bot that uses the knowledge base to respond to customer requests. You need to identify what the bot can perform without adding additional skills. What should you identify?
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

You have an app that identifies the coordinates of a product in an image of a supermarket shelf.
Which service does the app use?
In which two scenarios can you use the Azure Al Document Intelligence service (formerly Form Recognizer)? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

For each of the following statements, select Yes if the statement is True. Otherwise, select No. NOTE: Each correct selection is worth one point.

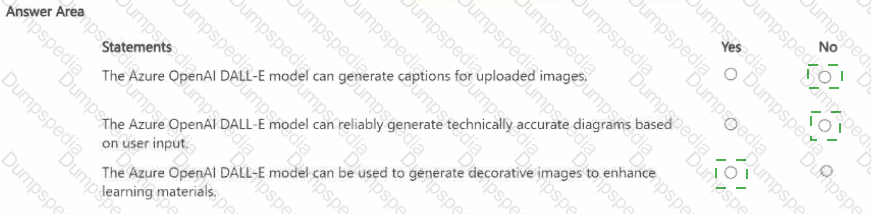
Which two actions can you perform by using the Azure OpenAI DALL-E model? Each correct answer presents a complete solution.
NOTE: Each correct answer is worth one point.
You need to predict the income range of a given customer by using the following dataset.
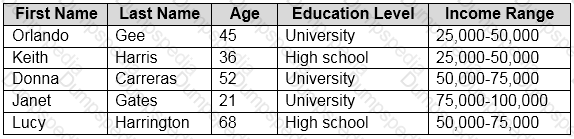
Which two fields should you use as features? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.

What should you do to ensure that an Azure OpenAI model generates accurate responses that include recent events?
Which Azure Machine Learning capability should you use to quickly build and deploy a predictive model without extensive coding?
In which two scenarios can you use speech recognition? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
Which Computer Vision feature can you use to generate automatic captions for digital photographs?
You ate building a Conversational Language Understanding model for an e-commerce business.
You need to ensure that the model detects when utterances are outside the intended scope of the model.
What should you do?
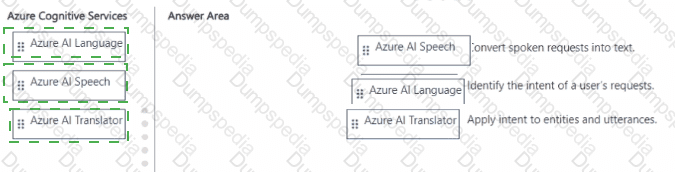
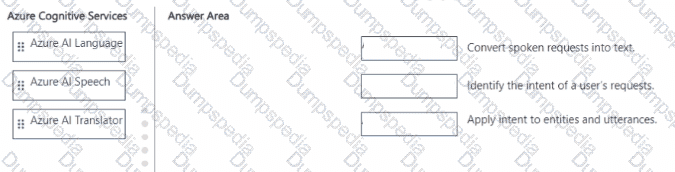
Match the Azure Al service to the appropriate actions.
To answer, drag the appropriate service from the column on the left to its action on the right Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
Which two languages can you use to write custom code for Azure Machine Learning designer? Each correct answer presents a complete solution.
NOTE; Each correct selection is worth one point.
You are developing a Chabot solution in Azure.
Which service should you use to determine a user’s intent?
You have an Azure Machine Learning pipeline that contains a Split Data module. The Split Data module outputs to a Train Model module and a Score Model module. What is the function of the Split Data module?
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.




TESTED 17 Jun 2026