A company is training a deep learning model to detect abnormalities in images. The company has limited GPU resources and a large hyperparameter space to explore. The company needs to test different configurations and avoid wasting computation time on poorly performing models that show weak validation accuracy in early epochs.
Which hyperparameter optimization strategy should the company use?
A company needs to update the model definition of an existing Amazon SageMaker Al endpoint.
Select and order the correct steps from the following list to update the model definition settings with the LEAST interruption of inferences. Select each step one time or not
at all. (Select and order THREE.)
Create a new endpoint configuration that uses the new model definition.
Create a new model definition with updated settings by using the CreateModel action in the SageMaker AI API.
Delete the endpoint that needs to be updated and recreate the endpoint with the new endpoint configuration.
Delete the IAM role and permissions for the ExecutionRoleArn parameter.
Update the endpoint with the new endpoint configuration.

A company wants to migrate ML models from an on-premises environment to Amazon SageMaker AI. The models are based on the PyTorch algorithm. The company needs to reuse its existing custom scripts as much as possible.
Which SageMaker AI feature should the company use?
A company uses Amazon Athena to query a dataset in Amazon S3. The dataset has a target variable that the company wants to predict.
The company needs to use the dataset in a solution to determine if a model can predict the target variable.
Which solution will provide this information with the LEAST development effort?
An ML engineer is developing a fraud detection model by using the Amazon SageMaker XGBoost algorithm. The model classifies transactions as either fraudulent or legitimate.
During testing, the model excels at identifying fraud in the training dataset. However, the model is inefficient at identifying fraud in new and unseen transactions.
What should the ML engineer do to improve the fraud detection for new transactions?
A company is creating an application that will recommend products for customers to purchase. The application will make API calls to Amazon Q Business. The company must ensure that responses from Amazon Q Business do not include the name of the company ' s main competitor.
Which solution will meet this requirement?
A hospital wants to predict patient outcomes for the coming year An ML engineer must improve several existing ML models that currently perform poorly.
Select the correct regularization method from the following list to improve each model Select each regularization method one time, more than one time, or not at all. (Select THREE.)
• L1 regularization
• L2 regularization
• Early stopping

A company has multiple models that are hosted on Amazon SageMaker Al. The models need to be re-trained. The requirements for each model are different, so the company needs to choose different deployment strategies to transfer all requests to a new model.
Select the correct strategy from the following list for each requirement. Select each strategy one time. (Select THREE.)
. Canary traffic shifting
. Linear traffic shifting guardrail
. All at once traffic shifting

Case study
An ML engineer is developing a fraud detection model on AWS. The training dataset includes transaction logs, customer profiles, and tables from an on-premises MySQL database. The transaction logs and customer profiles are stored in Amazon S3.
The dataset has a class imbalance that affects the learning of the model ' s algorithm. Additionally, many of the features have interdependencies. The algorithm is not capturing all the desired underlying patterns in the data.
Before the ML engineer trains the model, the ML engineer must resolve the issue of the imbalanced data.
Which solution will meet this requirement with the LEAST operational effort?
An ML engineer needs to deploy ML models to get inferences from large datasets in an asynchronous manner. The ML engineer also needs to implement scheduled monitoring of the data quality of the models. The ML engineer must receive alerts when changes in data quality occur.
Which solution will meet these requirements?
A company uses a batching solution to process data analytics each day. The company wants to build an analytics platform to provide near real-time updates. The company wants to use open source technology and does not want to manage or scale the infrastructure.
Which solution will meet these requirements?
An ML engineer has a custom container that performs k-fold cross-validation and logs an average F1 score during training. The ML engineer wants Amazon SageMaker AI Automatic Model Tuning (AMT) to select hyperparameters that maximize the average F1 score.
How should the ML engineer integrate the custom metric into SageMaker AI AMT?
An ML engineer is deploying a generative AI model-based customer support agent that uses Amazon SageMaker AI for inference. The customer support agent must respond to customer questions about topics such as shipping policies, refund processes, and account management. The generative AI model generates one token at a time.
Customers report dissatisfaction with how long the customer support agent takes to generate lengthy responses to questions. The ML engineer must apply an inference optimization technique to improve the performance of the customer support agent.
Which solution will meet this requirement?
An ML engineer needs to organize a large set of text documents into topics. The ML engineer will not know what the topics are in advance. The ML engineer wants to use built-in algorithms or pre-trained models available through Amazon SageMaker AI to process the documents.
Which solution will meet these requirements?
An ML engineer needs to use Amazon SageMaker to fine-tune a large language model (LLM) for text summarization. The ML engineer must follow a low-code no-code (LCNC) approach.
Which solution will meet these requirements?
An ML engineer is configuring auto scaling for an inference component of a model that runs behind an Amazon SageMaker AI endpoint. The ML engineer configures SageMaker AI auto scaling with a target tracking scaling policy set to 100 invocations per model per minute. The SageMaker AI endpoint scales appropriately during normal business hours. However, the ML engineer notices that at the start of each business day, there are zero instances available to handle requests, which causes delays in processing.
The ML engineer must ensure that the SageMaker AI endpoint can handle incoming requests at the start of each business day.
Which solution will meet this requirement?
An ML engineer needs to process thousands of existing CSV objects and new CSV objects that are uploaded. The CSV objects are stored in a central Amazon S3 bucket and have the same number of columns. One of the columns is a transaction date. The ML engineer must query the data based on the transaction date.
Which solution will meet these requirements with the LEAST operational overhead?
An ML engineer is using AWS CodeDeploy to deploy new container versions for inference on Amazon ECS.
The deployment must shift 10% of traffic initially, and the remaining 90% must shift within 10–15 minutes.
Which deployment configuration meets these requirements?
A company has significantly increased the amount of data that is stored as .csv files in an Amazon S3 bucket. Data transformation scripts and queries are now taking much longer than they used to take.
An ML engineer must implement a solution to optimize the data for query performance.
Which solution will meet this requirement with the LEAST operational overhead?
A company regularly receives new training data from the vendor of an ML model. The vendor delivers cleaned and prepared data to the company ' s Amazon S3 bucket every 3-4 days.
The company has an Amazon SageMaker pipeline to retrain the model. An ML engineer needs to implement a solution to run the pipeline when new data is uploaded to the S3 bucket.
Which solution will meet these requirements with the LEAST operational effort?
A company has used Amazon SageMaker to deploy a predictive ML model in production. The company is using SageMaker Model Monitor on the model. After a model update, an ML engineer notices data quality issues in the Model Monitor checks.
What should the ML engineer do to mitigate the data quality issues that Model Monitor has identified?
A company uses an Amazon EMR cluster to run a data ingestion process for an ML model. An ML engineer notices that the processing time is increasing.
Which solution will reduce the processing time MOST cost-effectively?
An ML engineer is developing a classification model. The ML engineer needs to use custom libraries in processing jobs, training jobs, and pipelines in Amazon SageMaker AI.
Which solution will provide this functionality with the LEAST implementation effort?
A company runs an ML model on Amazon SageMaker AI. The company uses an automatic process that makes API calls to create training jobs for the model. The company has new compliance rules that prohibit the collection of aggregated metadata from training jobs.
Which solution will prevent SageMaker AI from collecting metadata from the training jobs?
A company is developing a customer support AI assistant by using an Amazon Bedrock Retrieval Augmented Generation (RAG) pipeline. The AI assistant retrieves articles from a knowledge base stored in Amazon S3. The company uses Amazon OpenSearch Service to index the knowledge base. The AI assistant uses an Amazon Bedrock Titan Embeddings model for vector search.
The company wants to improve the relevance of the retrieved articles to improve the quality of the AI assistant ' s answers.
Which solution will meet these requirements?
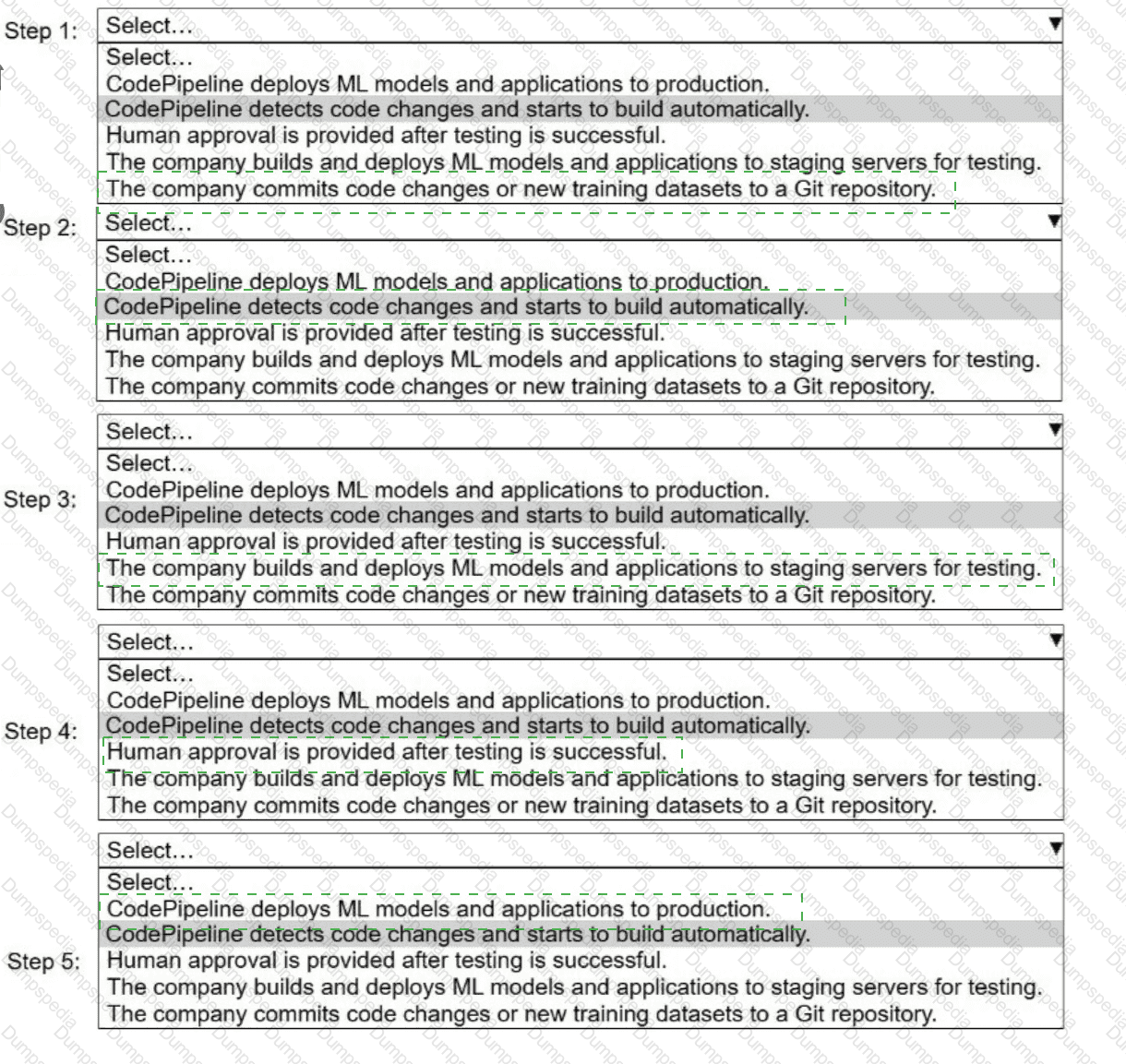
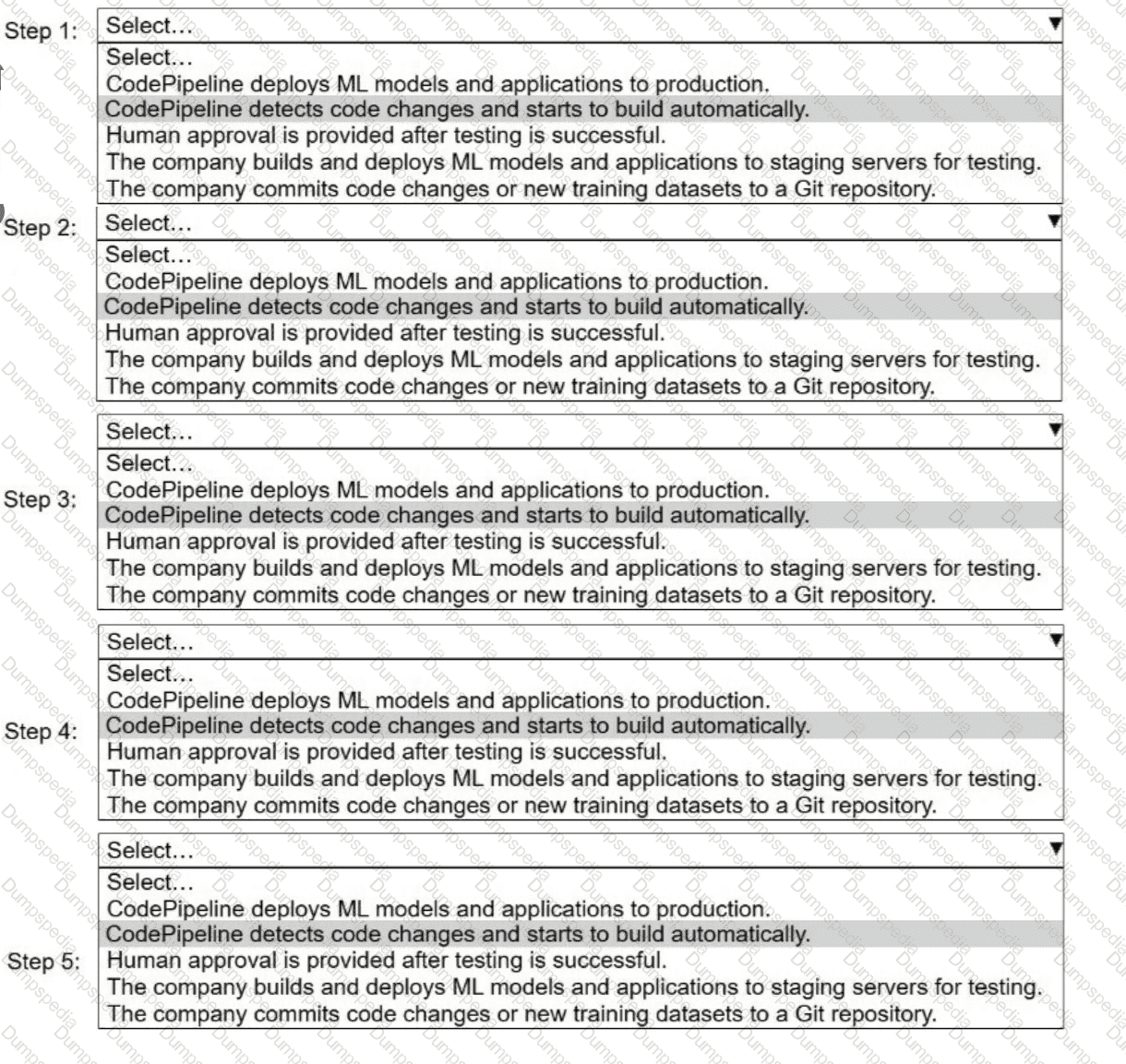
A company uses AWS CodePipeline to orchestrate a continuous integration and continuous delivery (CI/CD) pipeline for ML models and applications.
Select and order the steps from the following list to describe a CI/CD process for a successful deployment. Select each step one time. (Select and order FIVE.)
. CodePipeline deploys ML models and applications to production.
· CodePipeline detects code changes and starts to build automatically.
. Human approval is provided after testing is successful.
. The company builds and deploys ML models and applications to staging servers for testing.
. The company commits code changes or new training datasets to a Git repository.
A gaming company needs to deploy a natural language processing (NLP) model to moderate a chat forum in a game. The workload experiences heavy usage during evenings and weekends but minimal activity during other hours.
Which solution will meet these requirements MOST cost-effectively?
A company is developing a generative AI conversational interface to assist customers with payments. The company wants to use an ML solution to detect customer intent. The company does not have training data to train a model.
Which solution will meet these requirements?
A company wants to use Amazon SageMaker AI to host an ML model that runs on CPU for real-time predictions. The model has intermittent traffic during business hours and periods of no traffic after business hours.
Which hosting option will serve inference requests in the MOST cost-effective manner?
An ML engineer is training an XGBoost regression model in Amazon SageMaker AI. The ML engineer conducts several rounds of hyperparameter tuning with random grid search. After these rounds of tuning, the error rate on the test hold-out dataset is much larger than the error rate on the training dataset.
The ML engineer needs to make changes before running the hyperparameter grid search again.
Which changes will improve the model ' s performance? (Select TWO.)
A company uses Amazon SageMaker Studio to develop an ML model. The company has a single SageMaker Studio domain. An ML engineer needs to implement a solution that provides an automated alert when SageMaker compute costs reach a specific threshold.
Which solution will meet these requirements?
A company wants to develop an ML model by using tabular data from its customers. The data contains meaningful ordered features with sensitive information that should not be discarded. An ML engineer must ensure that the sensitive data is masked before another team starts to build the model.
Which solution will meet these requirements?
A company ' s ML engineer has deployed an ML model for sentiment analysis to an Amazon SageMaker endpoint. The ML engineer needs to explain to company stakeholders how the model makes predictions.
Which solution will provide an explanation for the model ' s predictions?
An ML engineer has developed a binary classification model outside of Amazon SageMaker. The ML engineer needs to make the model accessible to a SageMaker Canvas user for additional tuning.
The model artifacts are stored in an Amazon S3 bucket. The ML engineer and the Canvas user are part of the same SageMaker domain.
Which combination of requirements must be met so that the ML engineer can share the model with the Canvas user? (Choose two.)
An ML engineer needs to deploy ML models to get inferences from large datasets in an asynchronous manner. The ML engineer also needs to implement scheduled monitoring of data quality for the models and must receive alerts when changes in data quality occur.
Which solution will meet these requirements?
A company wants to predict the success of advertising campaigns by considering the color scheme of each advertisement. An ML engineer is preparing data for a neural network model. The dataset includes color information as categorical data.
Which technique for feature engineering should the ML engineer use for the model?
A company launches a feature that predicts home prices. An ML engineer trained a regression model using the SageMaker AI XGBoost algorithm. The model performs well on training data but underperforms on real-world validation data.
Which solution will improve the validation score with the LEAST implementation effort?
A company uses Amazon SageMaker for its ML workloads. The company ' s ML engineer receives a 50 MB Apache Parquet data file to build a fraud detection model. The file includes several correlated columns that are not required.
What should the ML engineer do to drop the unnecessary columns in the file with the LEAST effort?
An ML engineer develops a neural network model to predict whether customers will continue to subscribe to a service. The model performs well on training data. However, the accuracy of the model decreases significantly on evaluation data.
The ML engineer must resolve the model performance issue.
Which solution will meet this requirement?
An ML engineer is tuning an image classification model that performs poorly on one of two classes. The poorly performing class represents an extremely small fraction of the training dataset.
Which solution will improve the model’s performance?
A company is developing ML models by using PyTorch and TensorFlow estimators with Amazon SageMaker AI. An ML engineer configures the SageMaker AI estimator and now needs to initiate a training job that uses a training dataset.
Which SageMaker AI SDK method can initiate the training job?
An ML engineer needs to use AWS CloudFormation to create an ML model that an Amazon SageMaker endpoint will host.
Which resource should the ML engineer declare in the CloudFormation template to meet this requirement?
A company uses an ML model to recommend videos to users. The model is deployed on Amazon SageMaker AI. The model performed well initially after deployment, but the model ' s performance has degraded over time.
Which solution can the company use to identify model drift in the future?
A company is developing an application that reads animal descriptions from user prompts and generates images based on the information in the prompts. The application reads a message from an Amazon Simple Queue Service (Amazon SQS) queue. Then the application uses Amazon Titan Image Generator on Amazon Bedrock to generate an image based on the information in the message. Finally, the application removes the message from SQS queue.
Which IAM permissions should the company assign to the application ' s IAM role? (Select TWO.)
A company has an ML model that is deployed to an Amazon SageMaker AI endpoint for real-time inference. The company needs to deploy a new model. The company must compare the new model’s performance to the currently deployed model ' s performance before shifting all traffic to the new model.
Which solution will meet these requirements with the LEAST operational effort?
A company is building a deep learning model on Amazon SageMaker. The company uses a large amount of data as the training dataset. The company needs to optimize the model ' s hyperparameters to minimize the loss function on the validation dataset.
Which hyperparameter tuning strategy will accomplish this goal with the LEAST computation time?
A company needs to run a batch data-processing job on Amazon EC2 instances. The job will run during the weekend and will take 90 minutes to finish running. The processing can handle interruptions. The company will run the job every weekend for the next 6 months.
Which EC2 instance purchasing option will meet these requirements MOST cost-effectively?
A company is creating an ML model to identify defects in a product. The company has gathered a dataset and has stored the dataset in TIFF format in Amazon S3. The dataset contains 200 images in which the most common defects are visible. The dataset also contains 1,800 images in which there is no defect visible.
An ML engineer trains the model and notices poor performance in some classes. The ML engineer identifies a class imbalance problem in the dataset.
What should the ML engineer do to solve this problem?
An ML engineer is using Amazon Quick Suite (previously known as Amazon QuickSight) anomaly detection to detect very high or very low machine operating temperatures compared to normal. The ML engineer sets the Severity parameter to Low and above. The ML engineer sets the Direction parameter to All.
What effect will the ML engineer observe in the anomaly detection results if the ML engineer changes the Direction parameter to Lower than expected?
A company is using Amazon SageMaker and millions of files to train an ML model. Each file is several megabytes in size. The files are stored in an Amazon S3 bucket. The company needs to improve training performance.
Which solution will meet these requirements in the LEAST amount of time?
Case Study
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and features: ML experimentation, training, a
central model registry, model deployment, and model monitoring.
The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3.
The company must implement a manual approval-based workflow to ensure that only approved models can be deployed to production endpoints.
Which solution will meet this requirement?
A company runs an Amazon SageMaker domain in a public subnet of a newly created VPC. The network is configured properly, and ML engineers can access the SageMaker domain.
Recently, the company discovered suspicious traffic to the domain from a specific IP address. The company needs to block traffic from the specific IP address.
Which update to the network configuration will meet this requirement?
An ML engineer is using a training job to fine-tune a deep learning model in Amazon SageMaker Studio. The ML engineer previously used the same pre-trained model with a similar
dataset. The ML engineer expects vanishing gradient, underutilized GPU, and overfitting problems.
The ML engineer needs to implement a solution to detect these issues and to react in predefined ways when the issues occur. The solution also must provide comprehensive real-time metrics during the training.
Which solution will meet these requirements with the LEAST operational overhead?
An ML engineer needs to use an Amazon EMR cluster to process large volumes of data in batches. Any data loss is unacceptable.
Which instance purchasing option will meet these requirements MOST cost-effectively?
An ML engineer has trained an ML model by using Amazon SageMaker AI. The ML engineer determines that the model is overfitting and that the training data contains unnecessary features. The ML engineer must reduce the overfitting and the impact of the unnecessary features.
Which solution will meet these requirements?
A company needs to combine data from multiple sources. The company must use Amazon Redshift Serverless to query an AWS Glue Data Catalog database and underlying data that is stored in an Amazon S3 bucket.
Select and order the correct steps from the following list to meet these requirements. Select each step one time or not at all. (Select and order three.)
• Attach the IAM role to the Redshift cluster.
• Attach the IAM role to the Redshift namespace.
• Create an external database in Amazon Redshift to point to the Data Catalog schema.
• Create an external schema in Amazon Redshift to point to the Data Catalog database.
• Create an IAM role for Amazon Redshift to use to access only the S3 bucket that contains underlying data.
• Create an IAM role for Amazon Redshift to use to access the Data Catalog and the S3 bucket that contains underlying data.

An ML engineer wants to deploy a workflow that processes streaming IoT sensor data and periodically retrains ML models. The most recent model versions must be deployed to production.
Which service will meet these requirements?
An ML engineer is building an ML model in Amazon SageMaker AI. The ML engineer needs to load historical data directly from Amazon S3, Amazon Athena, and Snowflake into SageMaker AI.
Which solution will meet this requirement?
A company has trained an ML model in Amazon SageMaker. The company needs to host the model to provide inferences in a production environment.
The model must be highly available and must respond with minimum latency. The size of each request will be between 1 KB and 3 MB. The model will receive unpredictable bursts of requests during the day. The inferences must adapt proportionally to the changes in demand.
How should the company deploy the model into production to meet these requirements?
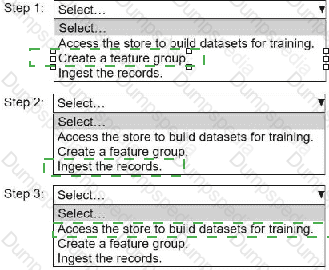
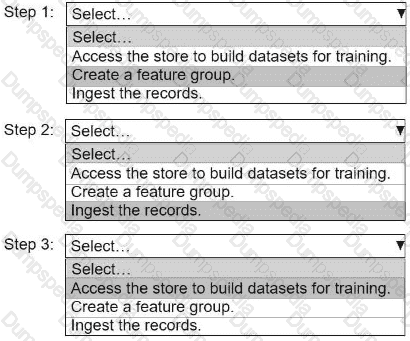
An ML engineer needs to use Amazon SageMaker Feature Store to create and manage features to train a model.
Select and order the steps from the following list to create and use the features in Feature Store. Each step should be selected one time. (Select and order three.)
• Access the store to build datasets for training.
• Create a feature group.
• Ingest the records.
A company is using an AWS Lambda function to monitor the metrics from an ML model. An ML engineer needs to implement a solution to send an email message when the metrics breach a threshold.
Which solution will meet this requirement?
A logistics company has installed in-vehicle cameras for basic monitoring of its drivers. The company wants to improve driver safety by identifying distractions that could lead to accidents.
Which solution will meet this requirement with the LEAST operational effort?
A company collects customer data every day. The company stores the data as compressed files in an Amazon S3 bucket that is partitioned by date. Every month, analysts download the data, process the data to check the data quality, and then upload the data to Amazon QuickSight dashboards.
An ML engineer needs to implement a solution to automatically check the data quality before the data is sent to QuickSight.
Which solution will meet these requirements with the LEAST operational overhead?
An ML engineer needs to use an ML model to predict the price of apartments in a specific location.
Which metric should the ML engineer use to evaluate the model’s performance?
A company ' s ML engineer is creating a classification model. The ML engineer explores the dataset and notices a column named day_of_week. The column contains the following values: Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, and Sunday.
Which technique should the ML engineer use to convert this column’s data to binary values?
A company is using Amazon SageMaker to create ML models. The company ' s data scientists need fine-grained control of the ML workflows that they orchestrate. The data scientists also need the ability to visualize SageMaker jobs and workflows as a directed acyclic graph (DAG). The data scientists must keep a running history of model discovery experiments and must establish model governance for auditing and compliance verifications.
Which solution will meet these requirements?
An ML engineering team is spread across multiple locations. When the lead ML engineer opens an Amazon SageMaker AI notebook, the ML engineer does not see the latest merged notebook made by other team members from a Git repository.
The lead ML engineer must see the latest SageMaker AI notebook updates.
Which solution will meet this requirement?
An ML engineer uses an Amazon SageMaker AI notebook instance to run a training job that trains a neural network model with an estimator. The training job loads data iteratively from an Amazon S3 path that is configured as an environment variable. The ML engineer viewed a profiling report of the training job. The ML engineer discovered that a substantial amount of the training time is spent during data loading.
How can the ML engineer improve the training speed?
A company uses a training job on Amazon SageMaker Al to train a neural network. The job first trains a model and then evaluates the model ' s performance ag
test dataset. The company uses the results from the evaluation phase to decide if the trained model will go to production.
The training phase takes too long. The company needs solutions that can shorten training time without decreasing the model ' s final performance.
Select the correct solutions from the following list to meet the requirements for each description. Select each solution one time or not at all. (Select THREE.)
. Change the epoch count.
. Choose an Amazon EC2 Spot Fleet.
· Change the batch size.
. Use early stopping on the training job.
· Use the SageMaker Al distributed data parallelism (SMDDP) library.
. Stop the training job.


TESTED 27 Jul 2026