You would like to measure how well an organization is achieving its goals.
What type of analysis should you perform?
A business intelligence engineer needs to reduce the size of a data model for reporting purposes. The data set contains more than one million rows, and the table has a date-time column named Date. Which of the following should the analyst do to complete this task?
An analyst needs to know what data an organization possesses. Which of the following is the best document for the analyst to consult?
A cereal manufacturer wants to determine whether the sugar content of its cereal has increased over the years. Which of the following is the appropriate descriptive statistic to use?
Consider two different datasets, one with gas prices and the other with food prices. Which of the following measures is most affected by outliers?
An analyst is updating a customer contacts database with information obtained from a survey of new customers. Which of the following data manipulation techniques should the analyst use?
A table in a hospital database has a column for patient height in inches and a column for patient height in centimeters. This is an example of:
A client has requested an analysis of all pet care items purchased by current customers and their social media connections in the past 12 months. Which of the following data analysis techniques would be the best choice given these requirements?
After a merger, an analyst needs to enhance a very complicated quarterly report so that it is more user friendly for new team members. Which of the following elements would help reduce questions?
A county in Illinois is conducting a survey to determine the mean annual income per household. The county is 427sq mi (2.65q km). Which of the following sampling methods would MOST likely result in a representative sample?
Which of the following describes the use of a representative amount of data from a main repository?
A column is being used to store strings of variable lengths. Performance is a concern, so the column needs to use as little space as possible. Which of the following data types best meets these requirements?
Which of the following is the most likely reason for a data analyst to optimize a query using parameterization?
Given the customer table below:
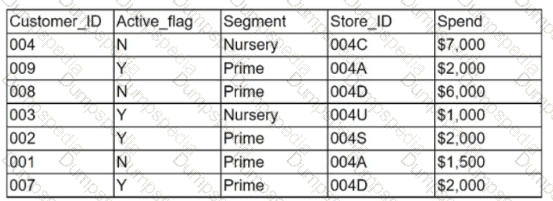
Which of the following chart types is the most appropriate to represent the average spending of active customers vs. inactive customers?
Which of the following describes the method of sampling in which elements of data are selected randomly from each of the small subgroups within a population?
An analyst wants to extract data from a variety of sources and store the data in a cloud-based environment prior to cleaning. Which of the following integration techniques should the analyst use?
A data analyst has been asked to merge the tables below, first performing an INNER JOIN and then a LEFT JOIN:
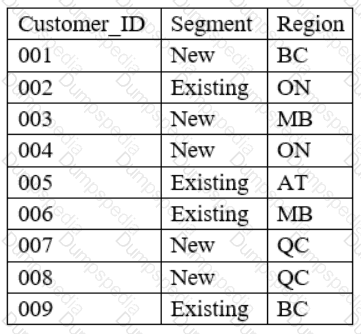
Customer Table -
In-store Transactions –
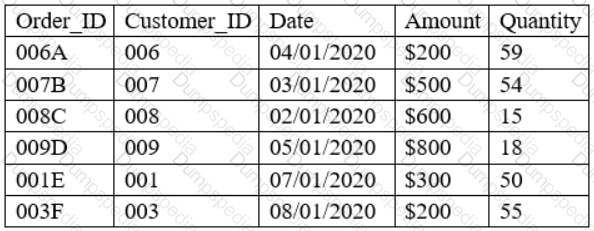
Which of the following describes the number of rows of data that can be expected after performing both joins in the order stated, considering the customer table as the main table?
Which of the following can be used to translate data into another form so it can only be read by a user who has a key or a password?
The process of performing initial investigations on data to spot outliers, discover patterns, and test assumptions with statistical insight and graphical visualization is called:
An analyst compiled a high-level report that includes the following data points:
Total dollars closed for the year
Annual quota/goal
Top 10 customers
Average deal size
Largest deals lost
Which of the following groups is the most likely audience for this report?
An employer needs to maintain adequate office staffing during the winter and wants to track storm data. Which of the following data collection methods should the employer use?
Angela is aggregating data from CRM system with data from an employee system.
While performing an initial quality check, she realizes that her employee ID is not associated with her identifier in the CRM system.
What kind of issues is Angela facing?
Choose the best answer.
A recurring event is being stored in two databases that are housed in different geographical locations. A data analyst notices the event is being logged three hours earlier in one database than in the other database. Which of the following is the MOST likely cause of the issue?
A reporting analyst needs to create a report that refreshes automatically and is accessible to the entire sales organization. Which of the following tools is the most appropriate to use for this task?
An analyst wants to create a historical data set for the past five years with each year in its own data set. Which of the following methods is the best way to create this historical data set?
Joe. an analyst. tests the loading time on a dashboard he is preparing to go live and finds it is slower than he would like. Which of the following must occur to decrease the loading time?
Which of the following is the best approach to use to gain a general understanding of a data set?
Each month an analyst needs to execute a data pull for the two prior months. Which of the following is the most efficient function for the analyst to use?
An organization would like to add a secondary email field to its customer database in order toenrich the customer profiles. Which of the following data manipulation techniques should the analyst use to add this information?
Given the following table:
Date of visit
Age
Gender
6/1/22
30
Male
6/15/22
65F
Fem.
6/19/2022
24
M
Which of the following describes the data quality issues with the age data?
Which of the following report types is most appropriate for a high-level, year-end report requested by a Chief Executive Officer?
Given the following table of student scores (with some values that violate the allowed scoring rules), which of the following is the best reason for cleansing the data?
You are working with a dataset and want to change the names of categories that you used fordifferent types of books.
What term best describes this action?
A business unit made the following modification to the values in a table:

Which of the following data quality dimensions was applied in this scenario?
An analyst is reviewing the following data:
Car IDSpeed
123155
566436
564418
650567
546436
645638
Which of the following should the analyst include in the measures of central tendency for speed?
A user receives a large custom report to track company sales across various date ranges. The user then completes a series of manual calculations for each date range. Which of the following should an analyst suggest so the user has a dynamic, seamless experience?
A data analyst must fulfill a request for information that is needed weekly and should be automatically emailed to a specific set of users. Which of the following types of reports should theanalyst recommend?
A survey asks participants to rate a company on a scale of one to ten. Which of the following best describes the rating variable?
A data analyst has removed the outliers from a data set due to large variances. Which of the following central tendencies would be the best measure to use?
A data analyst is setting up a data dashboard to monitor several ETL data streams to ensure that data is complete for later analysis. Which of the following audiences should the analyst target for this dashboard?
A data analyst is working with a team to create a dashboard for a client who requires on-demand access. Which of the following is the best delivery method to support the clients’ requirement?
Given the following graph:
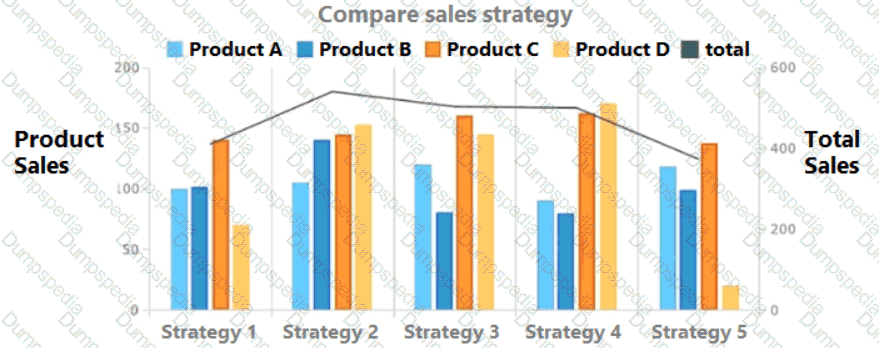
Which of the following summary statements upholds integrity in data reporting?
Given the following:

Which of the following is the most important thing for an analyst to do when transforming the table for a trend analysis?
Taylor wants to investigate how manufacturing, marketing, and sales expenditures impact overall profitability for her company.
Which of the following systems is the most appropriate?
An analyst wants to determine whether a relationship between an individual's age and voting preferences exists. Which of the following is the best statistical method for the analyst to use?
A sales manager requested a report that contains the first name, last name, and phone number of all of the company's customers and employees. The data engineer needs to return all the records from several tables, even duplicates. Which of the following is the best way to join the two tables?
An analyst in a consumer bank department wants to showcase the concentration of accounts opened in the United States by ZIP Code to describe the effectiveness of the bank's marketing campaigns. Which of the following would be the best way to visualize the data?
A database administrator is required to mask certain table columns containing PII in order to comply with the company privacy policy. Which of the following are the most likely types of information the administrator should mask? (Select two).
Which of the following data types would a telephone number formatted as XXX-XXX-XXXX be considered?
A data analyst has received a data set that contains actual and projected sales for the fourth quarter of 2019. Which of the following statistical methods should the analyst use to find the measure of dispersion?
Which of the following is a process that is used during data integration to collect, blend, and load data?
A database consists of one fact table that is composed of multiple dimensions. Each dimension is represented by a denormalized table. This structure is an example of a:
Which of the following BEST describes the issue in which character values are mixed with integer values in a data set column?
An analyst reviews the following data:
7
3
5
2
3
7
7
10
Which of the following is the value of the mode?
An analyst is building a new dashboard for a user. After an initial conversation with the user. the analyst created a mock-up of the dashboard. Which of the following best explains why the analyst created the mock-up?
An analyst is explaining the company’s financial systems and reporting tools to a new coworker. Which of the following data quality dimensions are the most important? (Select three).
A Chief Executive Officer (CEO) is requesting more up-to-date sales data for improved visibility prior to month-end. An analyst must determine the frequency of a sales report that was previously distributed on an as-needed basis. Which of the following would be the most appropriate frequency for this report?
A research analyst collects ten data points from 1.000 specimens. The analyst will not need any additional data to complete the analysis and will not need to retrieve information by specifier. Which of the following is the best data structure for the analyst to use?
A data analyst is attempting to understand how ice cream consumption is affected by different attributes. such as cost, temperature. and income level. Which of the following
regression analyses should the data analyst perform to understand this relationship?
Which of the following is the first step an analyst should perform upon receiving a business request for analysis?
A data analyst needs to present the results of an online marketing campaign to the marketing manager. The manager wants to see the most important KPIs and measure the return on marketing investment. Which of the following should the data analyst use to BEST communicate this information to the manager?
Given the following table:

Which of the following describes the data quality issues with theagedata?
Which of the following is a common data analytics tool that is also used as an interpreted, high-level, general-purpose programming language?
A quality assurance manager is examining tolerances in Internet of Things sensors. Which of the following is the best measure for the manager to calculate?
A data set for sales per month includes the following data:
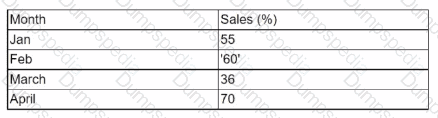
Which of the following cleaning and profiling methods should be applied to the data set?
An analyst reviews the following table:

Which of the following data types is represented in the values in the RefNo column?
‘Which of the following is the BEST reason to use database views instead of tables?
After completing web scraping, which of the following file formats needs to be parsed?
An e-commerce company recently tested a new website layout. The website was tested by a test group of customers, and an old website was presented to a control group. The table below shows the percentage of users in each group who made purchases on the websites:
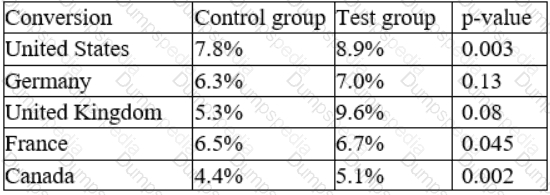
Which of the following conclusions is accurate at a 95% confidence interval?
Given the following tables:
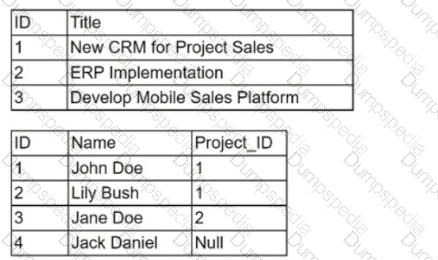
Which of the following will be the dimensions from a FULL JOIN of the tables above?
A data analyst is building a closed won quarter-over-quarter report for the sales team. Which of the following will be needed to complete this request?
A database consists of one fact table that is composed of multiple dimensions. Each dimension is represented by a denormalized table. This structure is an example of a:
An analyst needs to conduct a quick analysis. Which of the following is the FIRST step the analyst should perform with the data?
Daniel is using the structured Query language to work with data stored in relational database.
He would like to add several new rows to a database table.
What command should he use?
An analyst needs to determine the appropriate data type for the following sample data:
sample data collected:
Which of the following data types should be used for this data?
An analyst has written the following code:
SELECT *
FROM Cust_table
WHERE age > 60 AND City = "New York"
Which of the following criteria is the analyst retrieving?
Which one of the following programming languages is specifically designed for use in analytics applications?
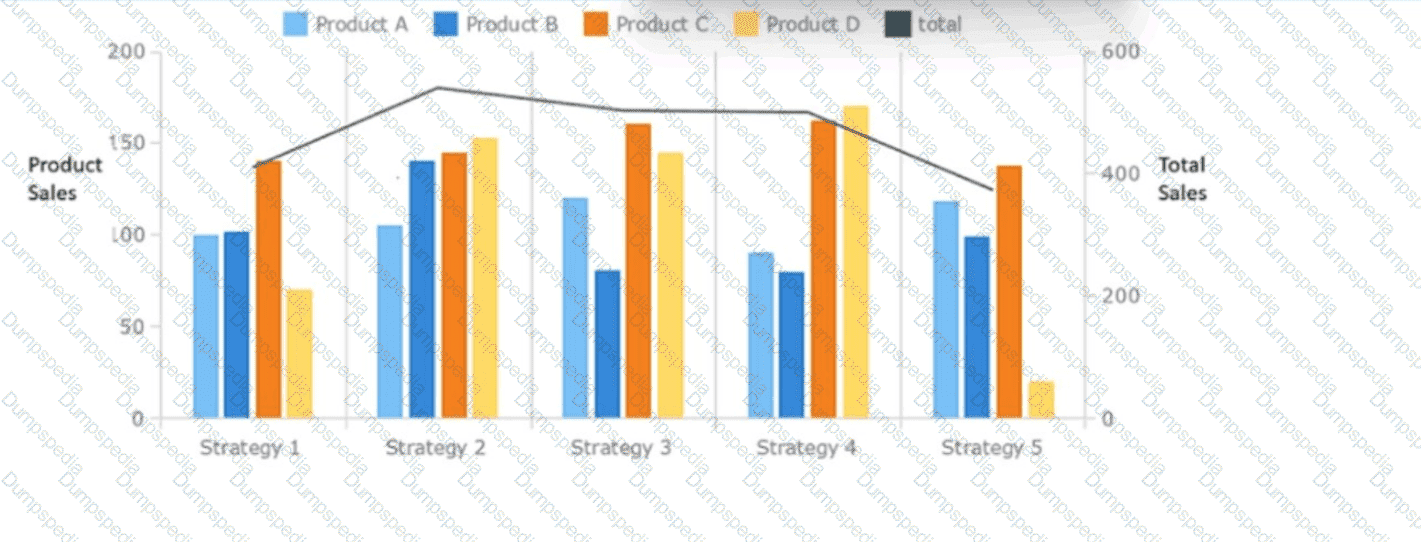
A data analyst is designing a dashboard that will provide a story of sales and determine which site is providing the highest sales volume per customer. The analyst must choose an appropriate chart to include in the dashboard. The following data is available:
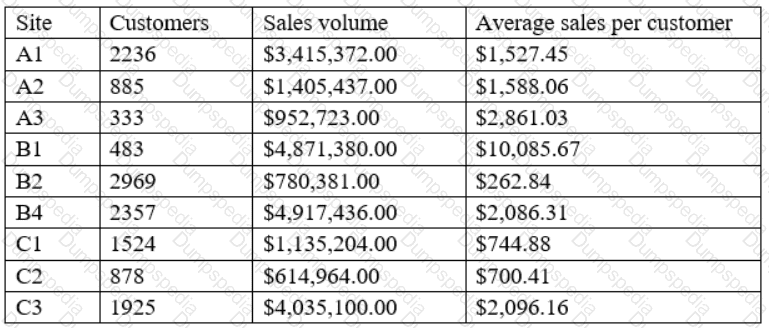
Which of the following types of charts should be considered?
Which of the following types of analyses should be used to evaluate the connections and anomalies in a data set when either known patterns are being violated or new patterns are emerging?
A data profiling rule checks the quality of all email addresses in a database. The rule returns a value with the number of email addresses that conformed to the rule. Which of the following options describes this value?
Given the following grocery store orders:
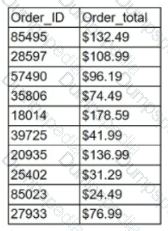
If a query is made to the table with the following logic:
Order_Total > 132 OR (Order Total >= 25 AND Order_Total < 74)
Which of the following is the number of orders that will be returned by the query?
Which of the following concepts should be applied if a data set with 40 fields needs to be pared down to 20 fields and contains similar data across multiple fields?
Jhon is working on an ELT process that sources data from six different source systems.
Looking at the source data, he finds that data about the sample people exists in two of six systems.
What does he have to make sure he checks for in his ELT process?
Choose the best answer.
An analyst must obtain the average daily sales for the following week:
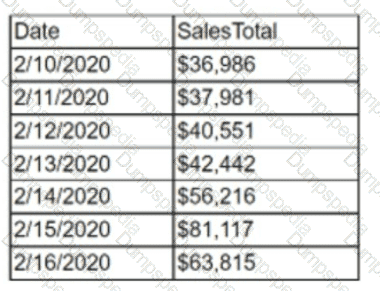
Which of the following must the analyst perform to obtain this value?
An analysts building a monthly report for production and wants to ensure the audience is aware of its once-a-month cadence. Which of the following is the MOST important to convey that information?
A dataset requires an analysis for investigating and discovering abnormalities. Which of the following best describes the nature of the exploratory analysis conducted?
Consider the following dataset which contains information about houses that are for sale:

Which of the following string manipulation commands will combine the address and region namecolumns to create a full address?
full_address------------------------- 85 Turner St, Northern Metropolitan 25 Bloomburg St, Northern Metropolitan 5 Charles St, Northern Metropolitan 40 Federation La, Northern Metropolitan 55a Park St, Northern Metropolitan
You are working with a dataset and need to swap the values in rows with those in columns.
What action do you need to perform?
A data analyst is working with a data set and would like to combine two fields into a single field. Which of the following data manipulation techniques should the analyst use?
Which of the following programming languages are best suited for analysis and machine-learning applications? (Select two).
Emma is working in a data warehouse and finds a finance fact table links to an organization dimension, which in turn links to a currency dimension that not linked to the fact table.
What type of design pattern is the data warehouse using?
An analyst has conducted a review of business questions. Which of the following should the analyst do next to conduct an analysis?
An analyst wants to check the progress and performance regarding the number of customers an organization served in the last six years. Which of the following represents the type of analysis theanalyst should perform?
An analyst for a concert venue is analyzing the number of tickets sold for a recent event. Which of the following types of data is the number of sold tickets an example of?
Which of the following defines the policies and procedures for managing the master data?
Which of the following is a common data analytics tool that is also used as an interpreted, high-level, general-purpose programming language?

TESTED 10 Jul 2026