Which of the following code blocks returns a DataFrame where columns predError and productId are removed from DataFrame transactionsDf?
Sample of DataFrame transactionsDf:
1.+-------------+---------+-----+-------+---------+----+
2.|transactionId|predError|value|storeId|productId|f |
3.+-------------+---------+-----+-------+---------+----+
4.|1 |3 |4 |25 |1 |null|
5.|2 |6 |7 |2 |2 |null|
6.|3 |3 |null |25 |3 |null|
7.+-------------+---------+-----+-------+---------+----+
The code block shown below should return a one-column DataFrame where the column storeId is converted to string type. Choose the answer that correctly fills the blanks in the code block to
accomplish this.
transactionsDf.__1__(__2__.__3__(__4__))
The code block displayed below contains an error. The code block should trigger Spark to cache DataFrame transactionsDf in executor memory where available, writing to disk where insufficient
executor memory is available, in a fault-tolerant way. Find the error.
Code block:
transactionsDf.persist(StorageLevel.MEMORY_AND_DISK)
The code block shown below should add column transactionDateForm to DataFrame transactionsDf. The column should express the unix-format timestamps in column transactionDate as string
type like Apr 26 (Sunday). Choose the answer that correctly fills the blanks in the code block to accomplish this.
transactionsDf.__1__(__2__, from_unixtime(__3__, __4__))
Which of the following code blocks returns a 2-column DataFrame that shows the distinct values in column productId and the number of rows with that productId in DataFrame transactionsDf?
Which of the following code blocks returns a DataFrame that has all columns of DataFrame transactionsDf and an additional column predErrorSquared which is the squared value of column
predError in DataFrame transactionsDf?
The code block displayed below contains an error. The code block should read the csv file located at path data/transactions.csv into DataFrame transactionsDf, using the first row as column header
and casting the columns in the most appropriate type. Find the error.
First 3 rows of transactions.csv:
1.transactionId;storeId;productId;name
2.1;23;12;green grass
3.2;35;31;yellow sun
4.3;23;12;green grass
Code block:
transactionsDf = spark.read.load("data/transactions.csv", sep=";", format="csv", header=True)
Which of the following code blocks returns a one-column DataFrame of all values in column supplier of DataFrame itemsDf that do not contain the letter X? In the DataFrame, every value should
only be listed once.
Sample of DataFrame itemsDf:
1.+------+--------------------+--------------------+-------------------+
2.|itemId| itemName| attributes| supplier|
3.+------+--------------------+--------------------+-------------------+
4.| 1|Thick Coat for Wa...|[blue, winter, cozy]|Sports Company Inc.|
5.| 2|Elegant Outdoors ...|[red, summer, fre...| YetiX|
6.| 3| Outdoors Backpack|[green, summer, t...|Sports Company Inc.|
7.+------+--------------------+--------------------+-------------------+
Which of the following code blocks generally causes a great amount of network traffic?
The code block displayed below contains an error. The code block below is intended to add a column itemNameElements to DataFrame itemsDf that includes an array of all words in column
itemName. Find the error.
Sample of DataFrame itemsDf:
1.+------+----------------------------------+-------------------+
2.|itemId|itemName |supplier |
3.+------+----------------------------------+-------------------+
4.|1 |Thick Coat for Walking in the Snow|Sports Company Inc.|
5.|2 |Elegant Outdoors Summer Dress |YetiX |
6.|3 |Outdoors Backpack |Sports Company Inc.|
7.+------+----------------------------------+-------------------+
Code block:
itemsDf.withColumnRenamed("itemNameElements", split("itemName"))
itemsDf.withColumnRenamed("itemNameElements", split("itemName"))
Which of the elements in the labeled panels represent the operation performed for broadcast variables?
Larger image
The code block shown below should write DataFrame transactionsDf as a parquet file to path storeDir, using brotli compression and replacing any previously existing file. Choose the answer that
correctly fills the blanks in the code block to accomplish this.
transactionsDf.__1__.format("parquet").__2__(__3__).option(__4__, "brotli").__5__(storeDir)
Which of the following code blocks produces the following output, given DataFrame transactionsDf?
Output:
1.root
2. |-- transactionId: integer (nullable = true)
3. |-- predError: integer (nullable = true)
4. |-- value: integer (nullable = true)
5. |-- storeId: integer (nullable = true)
6. |-- productId: integer (nullable = true)
7. |-- f: integer (nullable = true)
DataFrame transactionsDf:
1.+-------------+---------+-----+-------+---------+----+
2.|transactionId|predError|value|storeId|productId| f|
3.+-------------+---------+-----+-------+---------+----+
4.| 1| 3| 4| 25| 1|null|
5.| 2| 6| 7| 2| 2|null|
6.| 3| 3| null| 25| 3|null|
7.+-------------+---------+-----+-------+---------+----+
Which of the following code blocks reads in the JSON file stored at filePath, enforcing the schema expressed in JSON format in variable json_schema, shown in the code block below?
Code block:
1.json_schema = """
2.{"type": "struct",
3. "fields": [
4. {
5. "name": "itemId",
6. "type": "integer",
7. "nullable": true,
8. "metadata": {}
9. },
10. {
11. "name": "supplier",
12. "type": "string",
13. "nullable": true,
14. "metadata": {}
15. }
16. ]
17.}
18."""
Which of the following code blocks stores DataFrame itemsDf in executor memory and, if insufficient memory is available, serializes it and saves it to disk?
Which of the following code blocks reads in parquet file /FileStore/imports.parquet as a DataFrame?
Which of the following describes a way for resizing a DataFrame from 16 to 8 partitions in the most efficient way?
Which of the following code blocks returns a single-row DataFrame that only has a column corr which shows the Pearson correlation coefficient between columns predError and value in DataFrame
transactionsDf?
The code block displayed below contains an error. When the code block below has executed, it should have divided DataFrame transactionsDf into 14 parts, based on columns storeId and
transactionDate (in this order). Find the error.
Code block:
transactionsDf.coalesce(14, ("storeId", "transactionDate"))
Which of the following code blocks performs an inner join between DataFrame itemsDf and DataFrame transactionsDf, using columns itemId and transactionId as join keys, respectively?
Which of the following code blocks removes all rows in the 6-column DataFrame transactionsDf that have missing data in at least 3 columns?
Which of the following code blocks prints out in how many rows the expression Inc. appears in the string-type column supplier of DataFrame itemsDf?
Which of the following code blocks returns a DataFrame with a single column in which all items in column attributes of DataFrame itemsDf are listed that contain the letter i?
Sample of DataFrame itemsDf:
1.+------+----------------------------------+-----------------------------+-------------------+
2.|itemId|itemName |attributes |supplier |
3.+------+----------------------------------+-----------------------------+-------------------+
4.|1 |Thick Coat for Walking in the Snow|[blue, winter, cozy] |Sports Company Inc.|
5.|2 |Elegant Outdoors Summer Dress |[red, summer, fresh, cooling]|YetiX |
6.|3 |Outdoors Backpack |[green, summer, travel] |Sports Company Inc.|
7.+------+----------------------------------+-----------------------------+-------------------+
Which of the following code blocks displays the 10 rows with the smallest values of column value in DataFrame transactionsDf in a nicely formatted way?
The code block shown below should store DataFrame transactionsDf on two different executors, utilizing the executors' memory as much as possible, but not writing anything to disk. Choose the
answer that correctly fills the blanks in the code block to accomplish this.
1.from pyspark import StorageLevel
2.transactionsDf.__1__(StorageLevel.__2__).__3__
The code block displayed below contains an error. The code block should return DataFrame transactionsDf, but with the column storeId renamed to storeNumber. Find the error.
Code block:
transactionsDf.withColumn("storeNumber", "storeId")
Which of the following code blocks returns a DataFrame that is an inner join of DataFrame itemsDf and DataFrame transactionsDf, on columns itemId and productId, respectively and in which every
itemId just appears once?
Which of the following code blocks returns a copy of DataFrame transactionsDf where the column storeId has been converted to string type?
Which of the following code blocks applies the boolean-returning Python function evaluateTestSuccess to column storeId of DataFrame transactionsDf as a user-defined function?
Which of the following code blocks reads in the parquet file stored at location filePath, given that all columns in the parquet file contain only whole numbers and are stored in the most appropriate
format for this kind of data?
Which of the following code blocks sorts DataFrame transactionsDf both by column storeId in ascending and by column productId in descending order, in this priority?
Which of the following code blocks stores a part of the data in DataFrame itemsDf on executors?
Which of the following code blocks returns about 150 randomly selected rows from the 1000-row DataFrame transactionsDf, assuming that any row can appear more than once in the returned
DataFrame?
Which of the following code blocks returns all unique values of column storeId in DataFrame transactionsDf?
Which of the following code blocks reads JSON file imports.json into a DataFrame?
The code block shown below should return a copy of DataFrame transactionsDf with an added column cos. This column should have the values in column value converted to degrees and having
the cosine of those converted values taken, rounded to two decimals. Choose the answer that correctly fills the blanks in the code block to accomplish this.
Code block:
transactionsDf.__1__(__2__, round(__3__(__4__(__5__)),2))
Which of the following code blocks returns approximately 1000 rows, some of them potentially being duplicates, from the 2000-row DataFrame transactionsDf that only has unique rows?
The code block shown below should write DataFrame transactionsDf as a parquet file to path storeDir, using brotli compression and replacing any previously existing file. Choose the answer that
correctly fills the blanks in the code block to accomplish this.
transactionsDf.__1__.format("parquet").__2__(__3__).option(__4__, "brotli").__5__(storeDir)
The code block displayed below contains at least one error. The code block should return a DataFrame with only one column, result. That column should include all values in column value from
DataFrame transactionsDf raised to the power of 5, and a null value for rows in which there is no value in column value. Find the error(s).
Code block:
1.from pyspark.sql.functions import udf
2.from pyspark.sql import types as T
3.
4.transactionsDf.createOrReplaceTempView('transactions')
5.
6.def pow_5(x):
7. return x**5
8.
9.spark.udf.register(pow_5, 'power_5_udf', T.LongType())
10.spark.sql('SELECT power_5_udf(value) FROM transactions')
Which of the following code blocks writes DataFrame itemsDf to disk at storage location filePath, making sure to substitute any existing data at that location?
Which of the following DataFrame operators is never classified as a wide transformation?
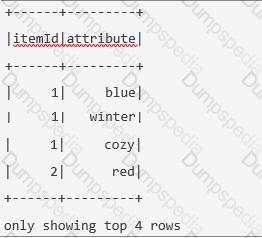
The code block displayed below contains an error. The code block should create DataFrame itemsAttributesDf which has columns itemId and attribute and lists every attribute from the attributes column in DataFrame itemsDf next to the itemId of the respective row in itemsDf. Find the error.
A sample of DataFrame itemsDf is below.

Code block:
itemsAttributesDf = itemsDf.explode("attributes").alias("attribute").select("attribute", "itemId")

TESTED 14 Jul 2026

 C:\Users\Admin\Desktop\Data\Odt data\Untitled.jpg
C:\Users\Admin\Desktop\Data\Odt data\Untitled.jpg
