A Spark application is experiencing performance issues in client mode because the driver is resource-constrained.
How should this issue be resolved?
23 of 55.
A data scientist is working with a massive dataset that exceeds the memory capacity of a single machine. The data scientist is considering using Apache Spark™ instead of traditional single-machine languages like standard Python scripts.
Which two advantages does Apache Spark™ offer over a normal single-machine language in this scenario? (Choose 2 answers)
A developer wants to refactor some older Spark code to leverage built-in functions introduced in Spark 3.5.0. The existing code performs array manipulations manually. Which of the following code snippets utilizes new built-in functions in Spark 3.5.0 for array operations?

A)

B)

C)

D)

24 of 55.
Which code should be used to display the schema of the Parquet file stored in the location events.parquet?
7 of 55.
A developer has been asked to debug an issue with a Spark application. The developer identified that the data being loaded from a CSV file is being read incorrectly into a DataFrame.
The CSV file has been read using the following Spark SQL statement:
CREATE TABLE locations
USING csv
OPTIONS (path '/data/locations.csv')
The first lines of the command SELECT * FROM locations look like this:
| city | lat | long |
| ALTI Sydney | -33... | ... |
Which parameter can the developer add to the OPTIONS clause in the CREATE TABLE statement to read the CSV data correctly again?
A data engineer is reviewing a Spark application that applies several transformations to a DataFrame but notices that the job does not start executing immediately.
Which two characteristics of Apache Spark's execution model explain this behavior?
Choose 2 answers:
In the code block below, aggDF contains aggregations on a streaming DataFrame:

Which output mode at line 3 ensures that the entire result table is written to the console during each trigger execution?
A Spark DataFrame df is cached using the MEMORY_AND_DISK storage level, but the DataFrame is too large to fit entirely in memory.
What is the likely behavior when Spark runs out of memory to store the DataFrame?
15 of 55.
A data engineer is working on a Streaming DataFrame (streaming_df) with the following streaming data:
id
name
count
timestamp
1
Delhi
20
2024-09-19T10:11
1
Delhi
50
2024-09-19T10:12
2
London
50
2024-09-19T10:15
3
Paris
30
2024-09-19T10:18
3
Paris
20
2024-09-19T10:20
4
Washington
10
2024-09-19T10:22
Which operation is supported with streaming_df?
26 of 55.
A data scientist at an e-commerce company is working with user data obtained from its subscriber database and has stored the data in a DataFrame df_user.
Before further processing, the data scientist wants to create another DataFrame df_user_non_pii and store only the non-PII columns.
The PII columns in df_user are name, email, and birthdate.
Which code snippet can be used to meet this requirement?
A data scientist of an e-commerce company is working with user data obtained from its subscriber database and has stored the data in a DataFrame df_user. Before further processing the data, the data scientist wants to create another DataFrame df_user_non_pii and store only the non-PII columns in this DataFrame. The PII columns in df_user are first_name, last_name, email, and birthdate.
Which code snippet can be used to meet this requirement?
A data engineer needs to write a Streaming DataFrame as Parquet files.
Given the code:

Which code fragment should be inserted to meet the requirement?
A)

B)
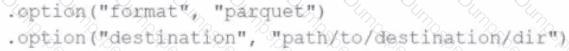
C)

D)
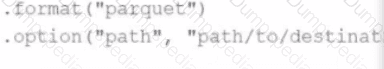
Which code fragment should be inserted to meet the requirement?
Given:
python
CopyEdit
spark.sparkContext.setLogLevel("
Which set contains the suitable configuration settings for Spark driver LOG_LEVELs?
Which UDF implementation calculates the length of strings in a Spark DataFrame?
1 of 55. A data scientist wants to ingest a directory full of plain text files so that each record in the output DataFrame contains the entire contents of a single file and the full path of the file the text was read from.
The first attempt does read the text files, but each record contains a single line. This code is shown below:
txt_path = "/datasets/raw_txt/*"
df = spark.read.text(txt_path) # one row per line by default
df = df.withColumn("file_path", input_file_name()) # add full path
Which code change can be implemented in a DataFrame that meets the data scientist's requirements?
A Spark developer is building an app to monitor task performance. They need to track the maximum task processing time per worker node and consolidate it on the driver for analysis.
Which technique should be used?
A data engineer is streaming data from Kafka and requires:
Minimal latency
Exactly-once processing guarantees
Which trigger mode should be used?
An engineer wants to join two DataFrames df1 and df2 on the respective employee_id and emp_id columns:
df1: employee_id INT, name STRING
df2: emp_id INT, department STRING
The engineer uses:
result = df1.join(df2, df1.employee_id == df2.emp_id, how='inner')
What is the behaviour of the code snippet?
2 of 55. Which command overwrites an existing JSON file when writing a DataFrame?
A data engineer observes that an upstream streaming source sends duplicate records, where duplicates share the same key and have at most a 30-minute difference in event_timestamp. The engineer adds:
dropDuplicatesWithinWatermark("event_timestamp", "30 minutes")
What is the result?
How can a Spark developer ensure optimal resource utilization when running Spark jobs in Local Mode for testing?
Options:
34 of 55.
A data engineer is investigating a Spark cluster that is experiencing underutilization during scheduled batch jobs.
After checking the Spark logs, they noticed that tasks are often getting killed due to timeout errors, and there are several warnings about insufficient resources in the logs.
Which action should the engineer take to resolve the underutilization issue?
A data engineer is working on a Streaming DataFrame streaming_df with the given streaming data:
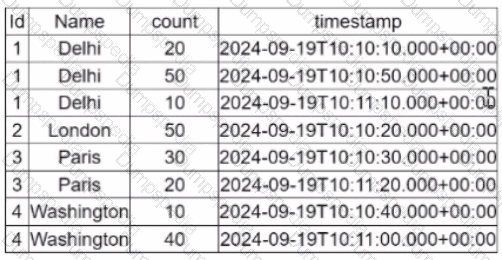
Which operation is supported with streamingdf ?
What is the relationship between jobs, stages, and tasks during execution in Apache Spark?
Options:
8 of 55.
A data scientist at a large e-commerce company needs to process and analyze 2 TB of daily customer transaction data. The company wants to implement real-time fraud detection and personalized product recommendations.
Currently, the company uses a traditional relational database system, which struggles with the increasing data volume and velocity.
Which feature of Apache Spark effectively addresses this challenge?
36 of 55.
What is the main advantage of partitioning the data when persisting tables?
4 of 55.
A developer is working on a Spark application that processes a large dataset using SQL queries. Despite having a large cluster, the developer notices that the job is underutilizing the available resources. Executors remain idle for most of the time, and logs reveal that the number of tasks per stage is very low. The developer suspects that this is causing suboptimal cluster performance.
Which action should the developer take to improve cluster utilization?
A developer needs to produce a Python dictionary using data stored in a small Parquet table, which looks like this:

The resulting Python dictionary must contain a mapping of region -> region id containing the smallest 3 region_id values.
Which code fragment meets the requirements?
A)

B)

C)

D)

The resulting Python dictionary must contain a mapping of region -> region_id for the smallest 3 region_id values.
Which code fragment meets the requirements?
Given the following code snippet in my_spark_app.py:

What is the role of the driver node?
The following code fragment results in an error:
@F.udf(T.IntegerType())
def simple_udf(t: str) -> str:
return answer * 3.14159
Which code fragment should be used instead?
43 of 55.
An organization has been running a Spark application in production and is considering disabling the Spark History Server to reduce resource usage.
What will be the impact of disabling the Spark History Server in production?
A Spark application developer wants to identify which operations cause shuffling, leading to a new stage in the Spark execution plan.
Which operation results in a shuffle and a new stage?
A data engineer has been asked to produce a Parquet table which is overwritten every day with the latest data. The downstream consumer of this Parquet table has a hard requirement that the data in this table is produced with all records sorted by the market_time field.
Which line of Spark code will produce a Parquet table that meets these requirements?
20 of 55.
What is the difference between df.cache() and df.persist() in Spark DataFrame?
A Spark engineer is troubleshooting a Spark application that has been encountering out-of-memory errors during execution. By reviewing the Spark driver logs, the engineer notices multiple "GC overhead limit exceeded" messages.
Which action should the engineer take to resolve this issue?
Given the code:

df = spark.read.csv("large_dataset.csv")
filtered_df = df.filter(col("error_column").contains("error"))
mapped_df = filtered_df.select(split(col("timestamp"), " ").getItem(0).alias("date"), lit(1).alias("count"))
reduced_df = mapped_df.groupBy("date").sum("count")
reduced_df.count()
reduced_df.show()
At which point will Spark actually begin processing the data?
An engineer has a large ORC file located at /file/test_data.orc and wants to read only specific columns to reduce memory usage.
Which code fragment will select the columns, i.e., col1, col2, during the reading process?

TESTED 14 Jul 2026
