Which of the following Structured Streaming queries is performing a hop from a Silver table to a Gold table?
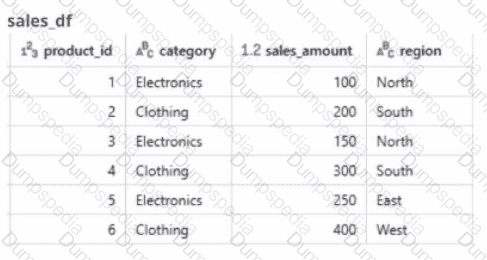
A global retail company sells products across multiple categories (e.g.. Electronics, Clothing) and regions (e.g.. North. South, East. West). The sales team has provided the data engineer with a PySpark dataframe named sales_df as below and the team wants the data engineer to analyze the sales data to help them make strategic decisions.
A data engineer is inspecting an ETL pipeline based on a Pyspark job that consistently encounters performance bottlenecks. Based on developer feedback, the data engineer assumes the job is low on compute resources. To pinpoint the issue, the data engineer observes the Spark Ul and finds out the job has a high CPU time vs Task time.
Which course of action should the data engineer take?
A data engineer wants to reduce costs and optimize cloud spending. The data engineer has decided to use Databricks Serverless for lowering cloud costs while maintaining existing SLAs.
What is the first step in migrating to Databricks Serverless?
A data engineer streams customer orders into a Kafka topic (orders_topic) and is currently writing the ingestion script of a DLT pipeline. The data engineer needs to ingest the data from Kafka brokers to DLT using Databricks
What is the correct code for ingesting the data?
A)

B)
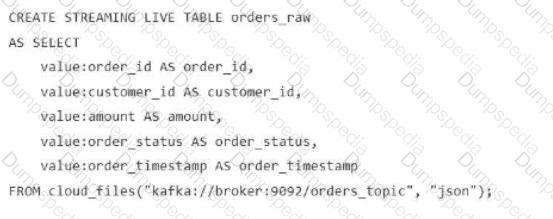
C)

D)

Which of the following describes a scenario in which a data team will want to utilize cluster pools?
What Databricks feature can be used to check the data sources and tables used in a workspace?
A data engineer has three tables in a Delta Live Tables (DLT) pipeline. They have configured the pipeline to drop invalid records at each table. They notice that some data is being dropped due to quality concerns at some point in the DLT pipeline. They would like to determine at which table in their pipeline the data is being dropped.
Which of the following approaches can the data engineer take to identify the table that is dropping the records?
A data engineer is using the OPTIMIZE command on a Delta table. What happens when OPTIMIZE is run twice on the same table with the same data?
A data engineer is working on a Databricks project that utilizes cloud storage. The data engineer wants to load several json files from containers on a storage account as soon as the file arrives within the storage account.
Which syntax should the data engineer follow to first load the files into a dataframe and check that it is working as expected using Python?
A data engineer is setting up access control in Unity Catalog and needs to ensure that a group of data analysts can query tables but not modify data.
Which permission should the data engineer grant to the data analysts?
An organization needs to share a dataset stored in its Databricks Unity Catalog with an external partner who uses a different data platform that is not Databricks. The goal is to maintain data security and ensure the partner can access the data efficiently.
Which method should the data engineer use to securely share the dataset with the external partner?
An organization is looking for an optimized storage layer that supports ACID transactions and schema enforcement. Which technology should the organization use?
A data engineer wants to create an external table in Databricks that references data stored in an Azure Data Lake Storage (ADLS) location. The goal is to enable Databricks to access and query this external data without moving it into Databricks-managed storage.
Which step should the data engineer take to successfully create the external table?
A single Job runs two notebooks as two separate tasks. A data engineer has noticed that one of the notebooks is running slowly in the Job’s current run. The data engineer asks a tech lead for help in identifying why this might be the case.
Which of the following approaches can the tech lead use to identify why the notebook is running slowly as part of the Job?
A data engineer has written a function in a Databricks Notebook to calculate the population of bacteria in a given medium.

Analysts use this function in the notebook and sometimes provide input arguments of the wrong data type, which can cause errors during execution.
Which Databricks feature will help the data engineer quickly identify if an incorrect data type has been provided as input?
A data engineer is attempting to drop a Spark SQL table my_table and runs the following command:
DROP TABLE IF EXISTS my_table;
After running this command, the engineer notices that the data files and metadata files have been deleted from the file system.
Which of the following describes why all of these files were deleted?
A data engineer has realized that the data files associated with a Delta table are incredibly small. They want to compact the small files to form larger files to improve performance.
Which of the following keywords can be used to compact the small files?
A data engineer has joined an existing project and they see the following query in the project repository:
CREATE STREAMING LIVE TABLE loyal_customers AS
SELECT customer_id -
FROM STREAM(LIVE.customers)
WHERE loyalty_level = ' high ' ;
Which of the following describes why the STREAM function is included in the query?
A data engineer has a single-task Job that runs each morning before they begin working. After identifying an upstream data issue, they need to set up another task to run a new notebook prior to the original task.
Which of the following approaches can the data engineer use to set up the new task?
A data engineer needs to ingest from both streaming and batch sources for a firm that relies on highly accurate data. Occasionally, some of the data picked up by the sensors that provide a streaming input are outside the expected parameters. If this occurs, the data must be dropped, but the stream should not fail.
Which feature of Delta Live Tables meets this requirement?
A company uses Delta Sharing to collaborate with partners across different cloud providers and geographic regions. What will result in additional costs due to cross-region or egress fees?
A new data engineering team has been assigned to work on a project. The team will need access to database customers in order to see what tables already exist. The team has its own group team.
Which of the following commands can be used to grant the necessary permission on the entire database to the new team?
A dataset has been defined using Delta Live Tables and includes an expectations clause:
CONSTRAINT valid_timestamp EXPECT (timestamp > ' 2020-01-01 ' ) ON VIOLATION DROP ROW
What is the expected behavior when a batch of data containing data that violates these constraints is processed?
A data engineer wants to schedule their Databricks SQL dashboard to refresh once per day, but they only want the associated SQL endpoint to be running when it is necessary.
Which of the following approaches can the data engineer use to minimize the total running time of the SQL endpoint used in the refresh schedule of their dashboard?
A data engineer needs to use a Delta table as part of a data pipeline, but they do not know if they have the appropriate permissions.
In which of the following locations can the data engineer review their permissions on the table?
A data engineer has a Python notebook in Databricks, but they need to use SQL to accomplish a specific task within a cell. They still want all of the other cells to use Python without making any changes to those cells.
Which of the following describes how the data engineer can use SQL within a cell of their Python notebook?
A data engineer and data analyst are working together on a data pipeline. The data engineer is working on the raw, bronze, and silver layers of the pipeline using Python, and the data analyst is working on the gold layer of the pipeline using SQL. The raw source of the pipeline is a streaming input. They now want to migrate their pipeline to use Delta Live Tables.
Which of the following changes will need to be made to the pipeline when migrating to Delta Live Tables?
Which of the following Git operations must be performed outside of Databricks Repos?
A data engineer needs to create a table in Databricks using data from a CSV file at location /path/to/csv.
They run the following command:

Which of the following lines of code fills in the above blank to successfully complete the task?
A Databricks single-task workflow fails at the last task due to an error in a notebook. The data engineer fixes the mistake in the notebook. What should the data engineer do to rerun the workflow?
A data engineering team has two tables. The first table march_transactions is a collection of all retail transactions in the month of March. The second table april_transactions is a collection of all retail transactions in the month of April. There are no duplicate records between the tables.
Which of the following commands should be run to create a new table all_transactions that contains all records from march_transactions and april_transactions without duplicate records?
Identify a scenario to use an external table.
A Data Engineer needs to create a parquet bronze table and wants to ensure that it gets stored in a specific path in an external location.
Which table can be created in this scenario?
A Python file is ready to go into production and the client wants to use the cheapest but most efficient type of cluster possible. The workload is quite small, only processing 10GBs of data with only simple joins and no complex aggregations or wide transformations.
Which cluster meets the requirement?
A data engineer works for an organization that must meet a stringent Service Level Agreement (SLA) that demands minimal runtime errors and high availability for its data processing pipelines. The data engineer wants to avoid the operational overhead of managing and tuning clusters.
Which architectural solution will meet the requirements?
Which of the following commands will return the location of database customer360?
Which query is performing a streaming hop from raw data to a Bronze table?
A)

B)

C)

D)

Which of the following must be specified when creating a new Delta Live Tables pipeline?
A data engineer needs to process SQL queries on a large dataset with fluctuating workloads. The workload requires automatic scaling based on the volume of queries, without the need to manage or provision infrastructure. The solution should be cost-efficient and charge only for the compute resources used during query execution.
Which compute option should the data engineer use?
A data engineer has a Job with multiple tasks that runs nightly. Each of the tasks runs slowly because the clusters take a long time to start.
Which of the following actions can the data engineer perform to improve the start up time for the clusters used for the Job?
A data engineer is processing ingested streaming tables and needs to filter out NULL values in the order_datetime column from the raw streaming table orders_raw and store the results in a new table orders_valid using DLT.
Which code snippet should the data engineer use?
A)
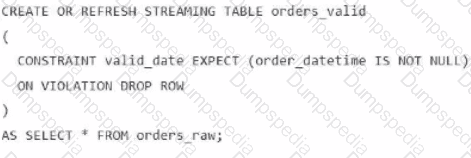
B)
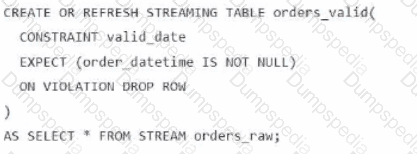
C)
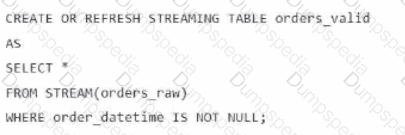
D)

A data engineer needs to optimize the data layout and query performance for an e-commerce transactions Delta table. The table is partitioned by " purchase_date " a date column which helps with time-based queries but does not optimize searches on user statistics " customer_id " , a high-cardinality column.
The table is usually queried with filters on " customer_i
d " within specific date ranges, but since this data is spread across multiple files in each partition, it results in full partition scans and increased runtime and costs.
How should the data engineer optimize the Data Layout for efficient reads?
A data engineer is maintaining a data pipeline. Upon data ingestion, the data engineer notices that the source data is starting to have a lower level of quality. The data engineer would like to automate the process of monitoring the quality level.
Which of the following tools can the data engineer use to solve this problem?
A data engineer at a company that uses Databricks with Unity Catalog needs to share a collection of tables with an external partner who also uses a Databricks workspace enabled for Unity Catalog. The data engineer decides to use Delta Sharing to accomplish this.
What is the first piece of information the data engineer should request from the external partner to set up Delta Sharing?
A data engineer has realized that they made a mistake when making a daily update to a table. They need to use Delta time travel to restore the table to a version that is 3 days old. However, when the data engineer attempts to time travel to the older version, they are unable to restore the data because the data files have been deleted.
Which of the following explains why the data files are no longer present?
A Databricks workflow fails at the last stage due to an error in a notebook. This workflow runs daily. The data engineer fixes the mistake and wants to rerun the pipeline. This workflow is very costly and time-intensive to run.
Which action should the data engineer do in order to minimise downtime and cost?
A data engineer is developing a small proof of concept in a notebook. When running the entire notebook, cluster usage spikes. The data engineer wants to keep the development experience and get real-time results.
Which cluster meets these requirements?

TESTED 14 Jul 2026
