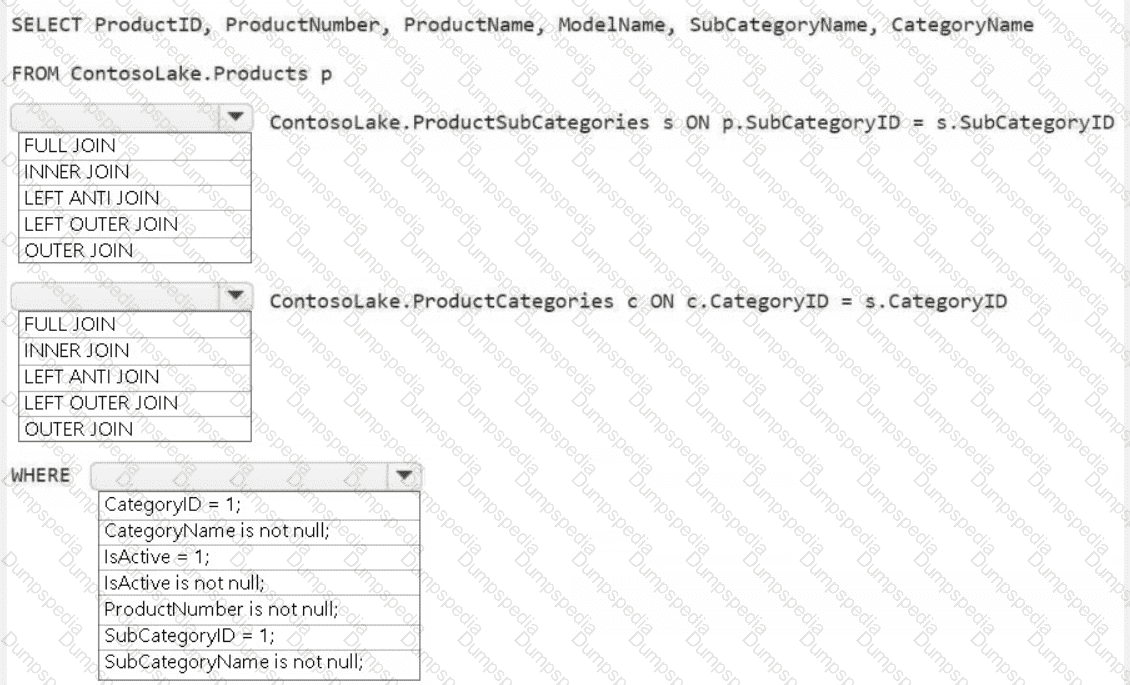
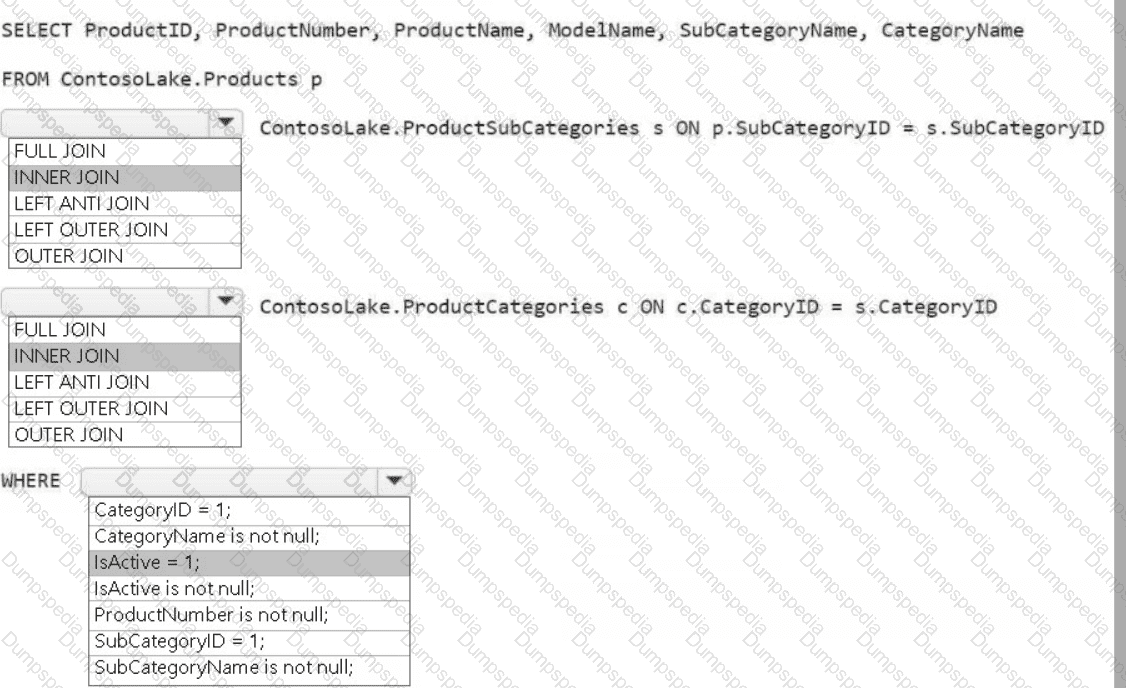
You need to create the product dimension.
How should you complete the Apache Spark SQL code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to schedule the population of the medallion layers to meet the technical requirements.
What should you do?
HOTSPOT
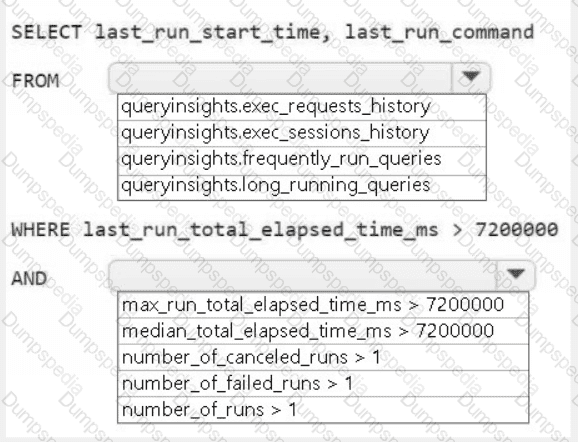
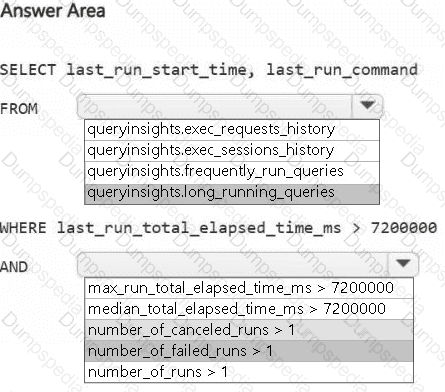
You need to troubleshoot the ad-hoc query issue.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to recommend a solution to resolve the MAR1 connectivity issues. The solution must minimize development effort. What should you recommend?
You have a table in a Fabric lakehouse that contains the following data.
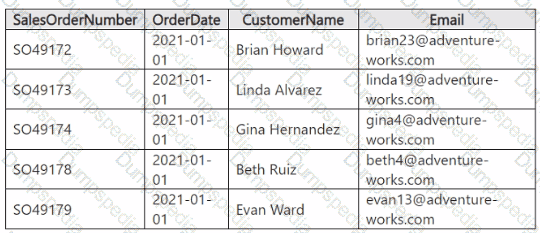
You have a notebook that contains the following code segment.

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

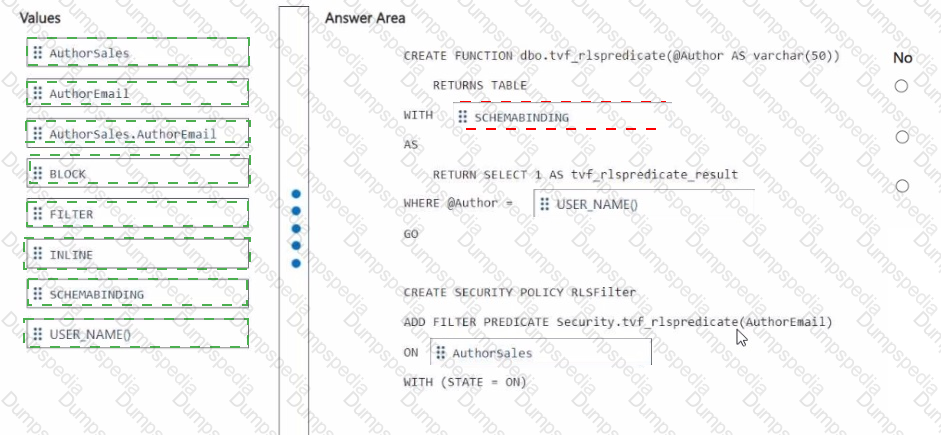
You need to ensure that the authors can see only their respective sales data.
How should you complete the statement? To answer, drag the appropriate values the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content
NOTE: Each correct selection is worth one point.

You need to ensure that processes for the bronze and silver layers run in isolation How should you configure the Apache Spark settings?
You need to resolve the sales data issue. The solution must minimize the amount of data transferred.
What should you do?
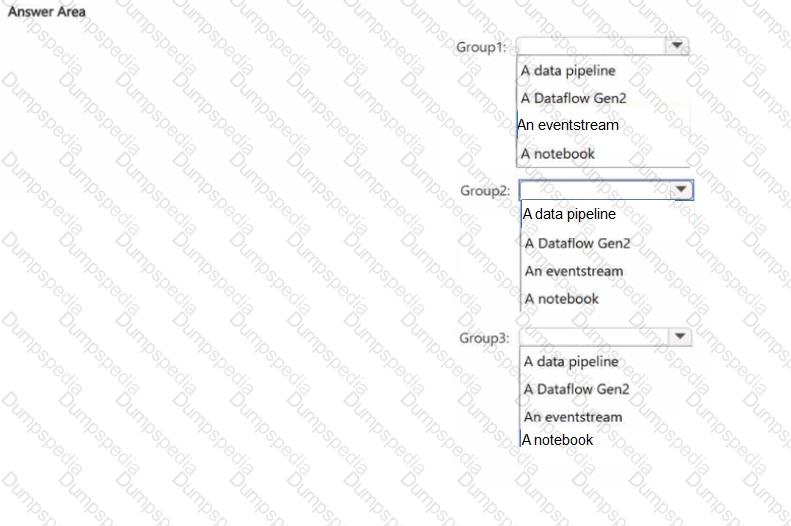
You have the development groups shown in the following table.

You have the projects shown in the following table.

You need to recommend which Fabric item to use based on each development group ' s skillset The solution must meet the project requirements and minimize development effort
What should you recommend for each group? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have a Fabric capacity that contains a workspace named Workspace1. Workspace1 contains a lakehouse named Lakehouse1, a data pipeline, a notebook, and several Microsoft Power BI reports.
A user named User1 wants to use SQL to analyze the data in Lakehouse1.
You need to configure access for User1. The solution must meet the following requirements:
Provide User1 with read access to the table data in Lakehouse1.
Prevent User1 from using Apache Spark to query the underlying files in Lakehouse1.
Prevent User1 from accessing other items in Workspace1.
What should you do?
HOTSPOT
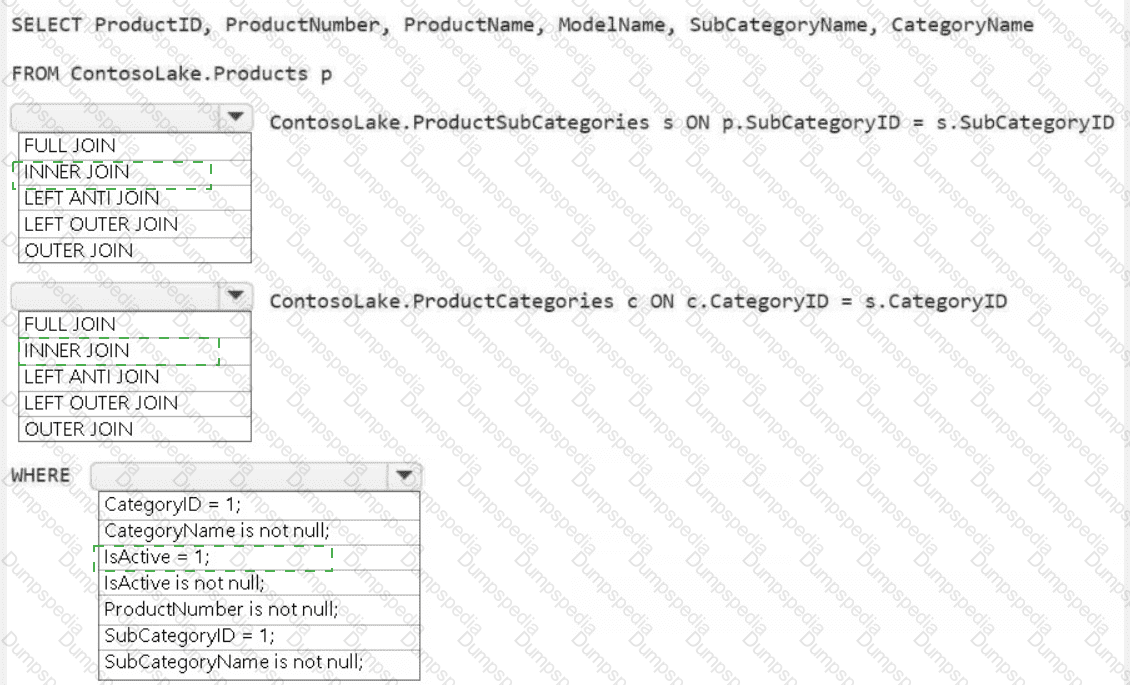
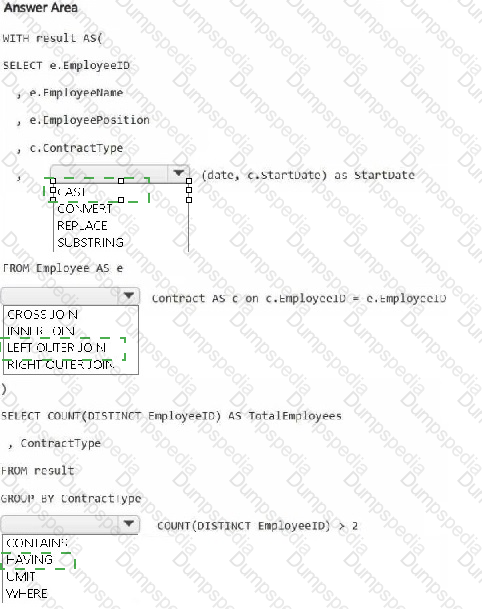
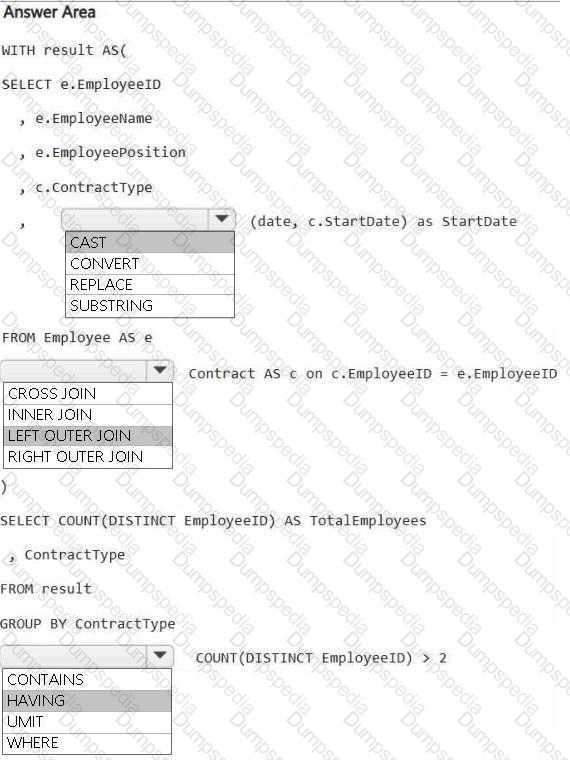
You have a Fabric workspace that contains a warehouse named Warehouse1. Warehouse1 contains the following tables and columns.
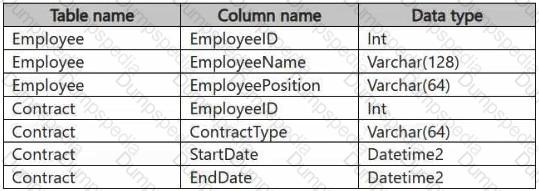
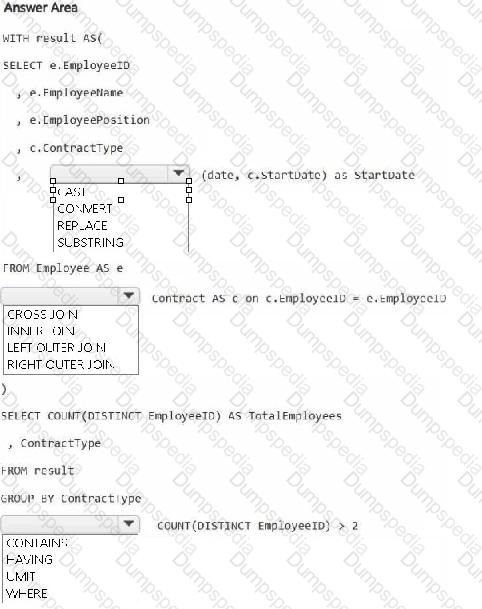
You need to denormalize the tables and include the ContractType and StartDate columns in the Employee table. The solution must meet the following requirements:
Ensure that the StartDate column is of the date data type.
Ensure that all the rows from the Employee table are preserved and include any matching rows from the Contract table.
Ensure that the result set displays the total number of employees per contract type for all the contract types that have more than two employees.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have an Azure subscription that contains a blob storage account named sa1. Sa1 contains two files named Filelxsv and File2.csv.
You have a Fabric tenant that contains the items shown in the following table.
You need to configure Pipeline1 to perform the following actions:
• At 2 PM each day, process Filel.csv and load the file into flhl.
• At 5 PM each day. process File2.csv and load the file into flhl.
The solution must minimize development effort. What should you use?
You have a Fabric workspace that contains a lakehouse and a notebook named Notebook1. Notebook1 reads data into a DataFrame from a table named Table1 and applies transformation logic. The data from the DataFrame is then written to a new Delta table named Table2 by using a merge operation.
You need to consolidate the underlying Parquet files in Table1.
Which command should you run?
You have a KQL database that contains a table named Readings.
You need to build a KQL query to compare the Meter-Reading value of each row to the previous row base on the ilmestamp value
A sample of the expected output is shown in the following table.


You have a Fabric workspace that contains a lakehouse named Lakehouse1.
In an external data source, you have data files that are 500 GB each. A new file is added every day.
You need to ingest the data into Lakehouse1 without applying any transformations. The solution must meet the following requirements
Trigger the process when a new file is added.
Provide the highest throughput.
Which type of item should you use to ingest the data?
You have an Azure SQL database named DB1.
In a Fabric workspace, you deploy an eventstream named EventStreamDBI to stream record changes from DB1 into a lakehouse.
You discover that events are NOT being propagated to EventStreamDBI.
You need to ensure that the events are propagated to EventStreamDBI.
What should you do?
You need to ensure that usage of the data in the Amazon S3 bucket meets the technical requirements.
What should you do?
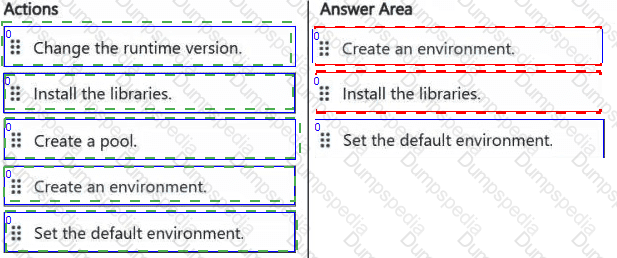
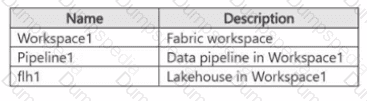
Your company has a team of developers. The team creates Python libraries of reusable code that is used to transform data.
You create a Fabric workspace name Workspace1 that will be used to develop extract, transform, and load (ETL) solutions by using notebooks.
You need to ensure that the libraries are available by default to new notebooks in Workspace1.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
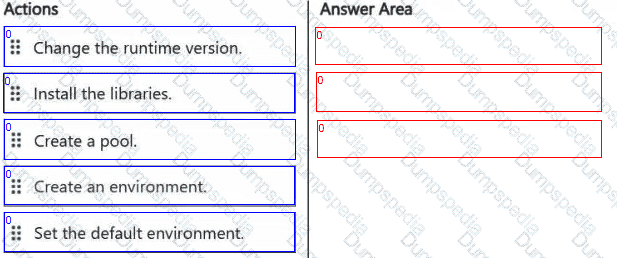
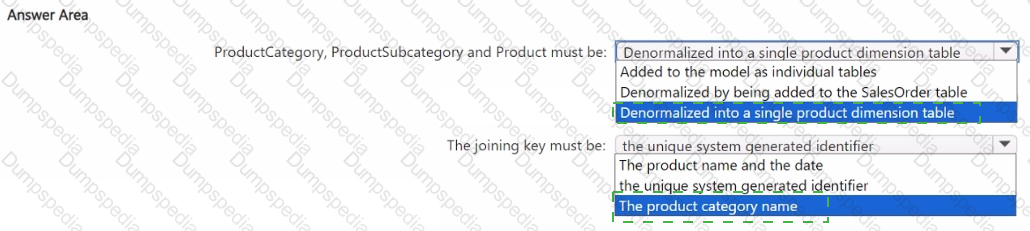
You have a Fabric warehouse named DW1 that contains four staging tables named ProductCategory, ProductSubcategory, Product, and SalesOrder. ProductCategory, ProductSubcategory, and Product are used often in analytical queries.
You need to implement a star schema for DW1. The solution must minimize development effort.
Which design approach should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have a Fabric deployment pipeline that uses three workspaces named Dev, Test, and Prod.
You need to deploy an eventhouse as part of the deployment process.
What should you use to add the eventhouse to the deployment process?
You have a Fabric warehouse named Warehouse1 that contains a table named Table1. Table 1 has a column named EmailAddress. All users have access to Warehouse1.
You need to configure dynamic data masking for the EmailAddress column. The solution must meet the following requirements:
• The solution must NOT change the data in Warehouse1.
• The solution must NOT require changes to the queries that access Table1.
• The solution must NOT require changes to the security or permissions granted to Warehouse1.
What should you use?



TESTED 20 Jun 2026
 A screenshot of a computer Description automatically generated
A screenshot of a computer Description automatically generated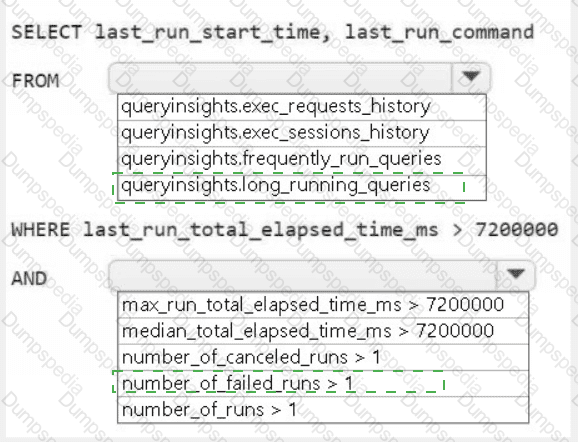
 A screenshot of a computer Description automatically generated
A screenshot of a computer Description automatically generated

 C:\Users\Waqas Shahid\Desktop\Mudassir\Untitled.jpg
C:\Users\Waqas Shahid\Desktop\Mudassir\Untitled.jpg